RESPONSIBLE JAVASCRIPT JEREMY WAGNER — @MALCHATA — JEREMY.CODES NDC OSLO — OSLO, NORWAY — JUNE 2019
Thank you everyone for attending. My name is Jeremy Wagner. I’m an independent web performance consultant, author, and speaker from Minnesota.
A presentation at NDC Oslo in June 2019 in Oslo, Norway by Jeremy Wagner

Thank you everyone for attending. My name is Jeremy Wagner. I’m an independent web performance consultant, author, and speaker from Minnesota.
This talk is based on a series of articles for A List Apart called Responsible JavaScript. Part II of the series was just released last week, and more parts will be published as the year goes on. If you like this talk, you’ll might like this article series. URLs to this and other materials in this talk will be in the conclusion.

To start, I’d like to talk about a word I stumbled on years ago. That word is “Sphexishness”. The word itself is unusual in that it’s a gold-plated adjective that’s not easily slipped into a free-wheeling conversation. But, it has relevance in the context of our work.

It refers to repetitive, seemingly factory-installed behavior. It’s also a word that’s hard to say if your mouth is still numb from a visit to the dentist. Or if you’ve had a couple drinks.

I promise you, that this is a talk about JavaScript, not entomology. Digging wasps, are, as you would expect, more sphexish than any other creature on Earth. They don’t act simply in deterministic and preprogrammed ways—they can also be easily manipulated, and be totally unaware of it.

These wasps provision their larva with paralyzed crickets. When they bring prey back to the nest, they have a strange routine. Before dragging the cricket into its nest, the wasp leaves it outside before entering the nest to inspect it. This is behavior that seems thoughtful at first, but it’s really quite mindless. Because, if an observer moves the cricket to another spot before the wasp reemerges, the wasp will once again set the cricket back to where it was before. Then it will inspect the nest—again. This cycle can be repeated endlessly, without the wasp ever realizing what’s going on.
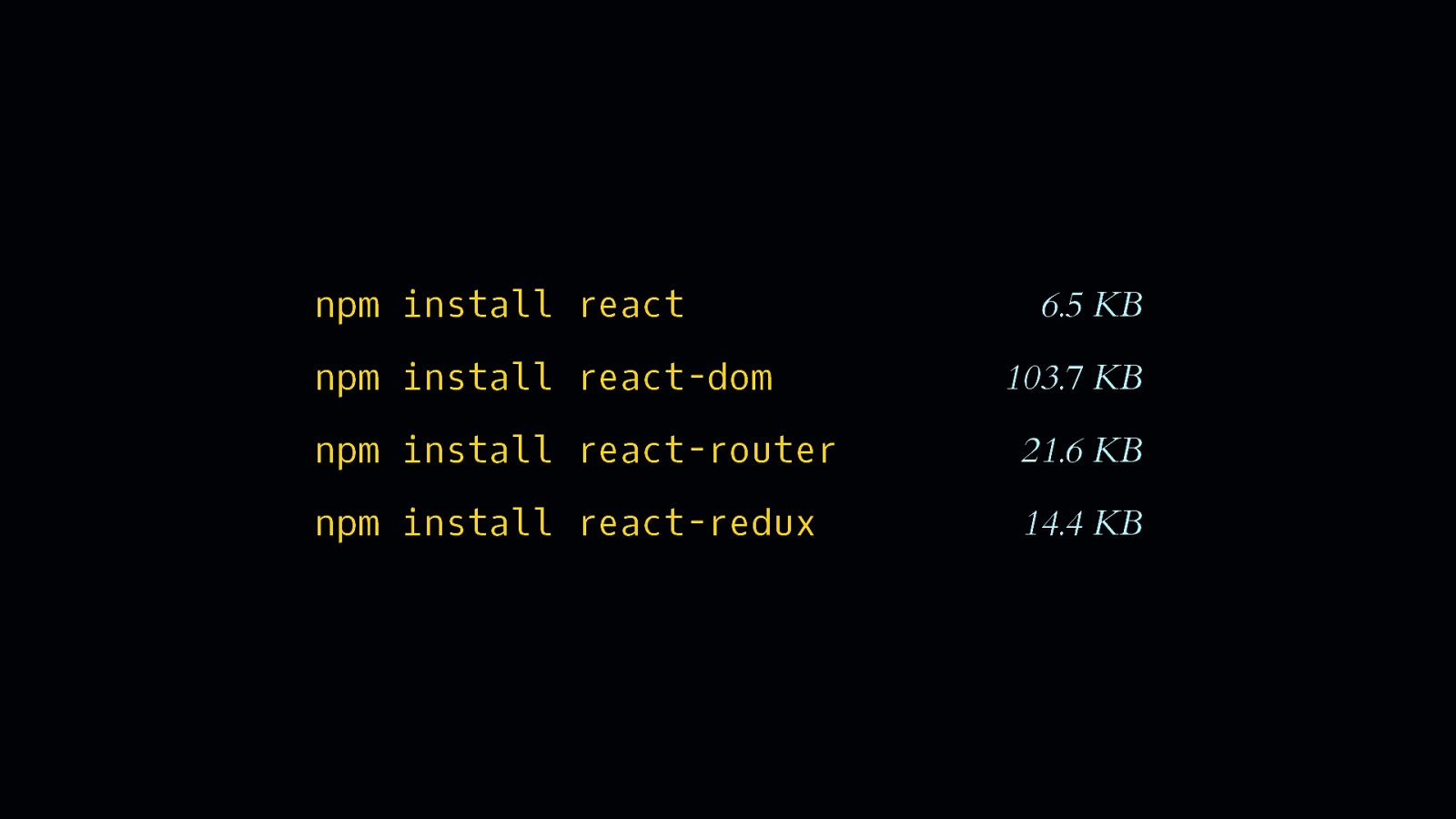
…and then possibly a state management tool—for the framework, of course… [SHOW REACT-REDUX] - …and all the while we’re unaware of—or perhaps have even made peace with—the overhead these conveniences bring.

Incidentally, have you ever opened a node_modules folder? It’s a place that, if a map was drawn of it during the 1400s, it would have illustrations of sea serpents with stern warnings like “here be dragons”. It’s a place we don’t go unless we need to—like if we’re debugging a module. That’s not to say we don’t know what’s in one npm package, but when you’re installing a bunch of them, it’s difficult to know what’s in all of them—and how much.
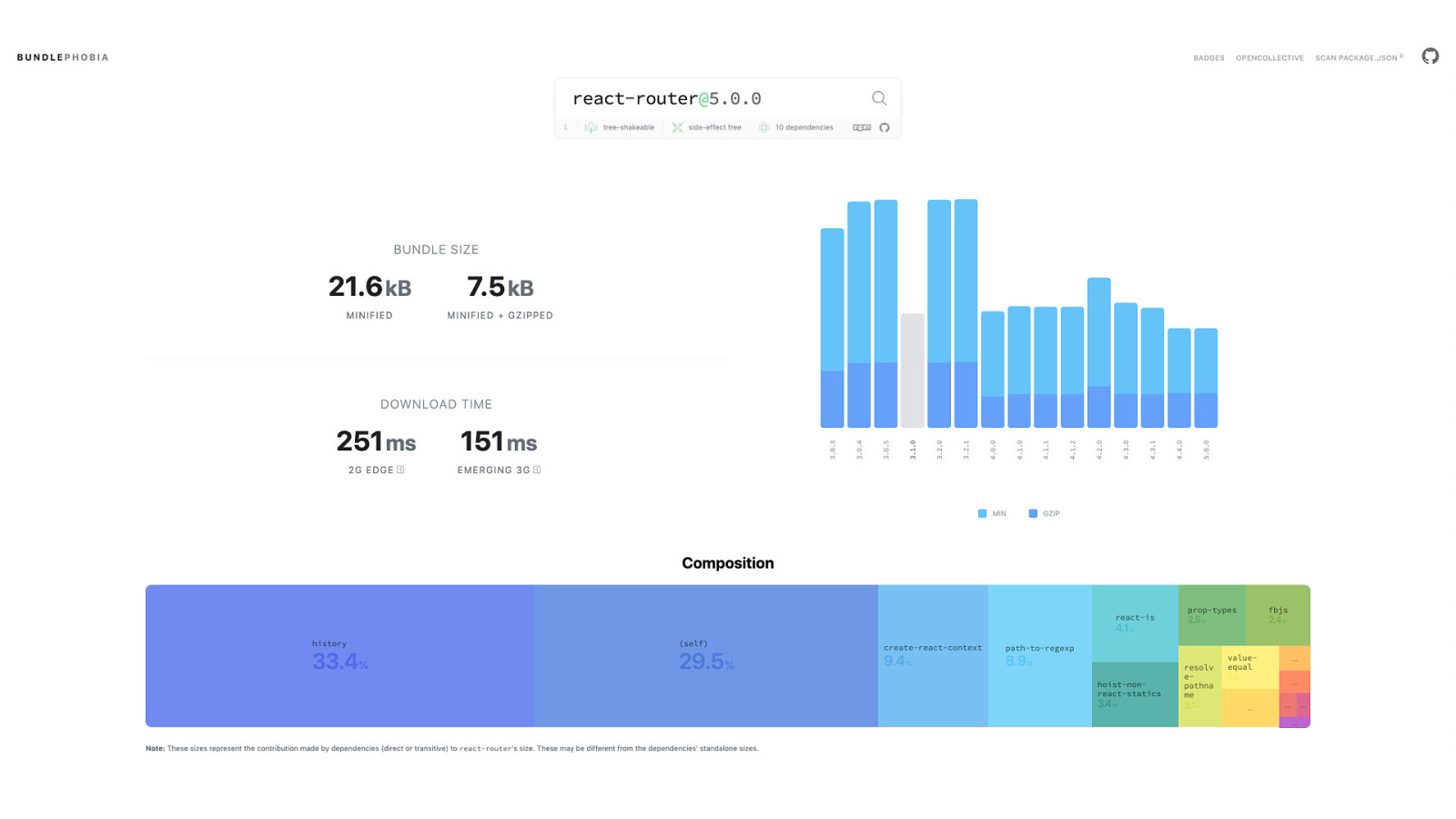
But even so, node_modules isn’t a black box—even if it seems like it at times. Tools such as Bundlephobia—shown here—can help us to understand not only what’s in a package, but also how much it can affect the performance of the stuff we build. That’s worth knowing.
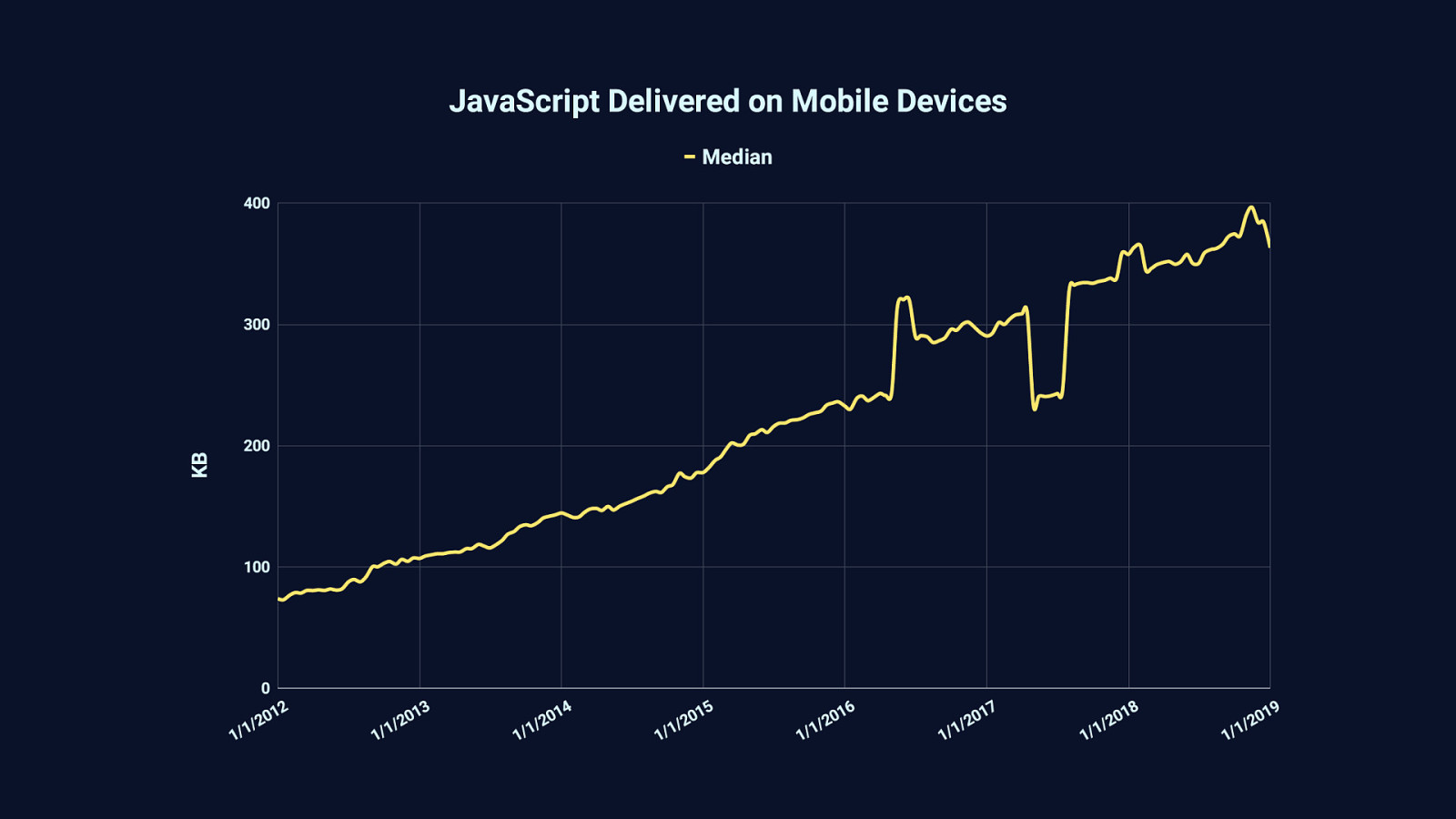
Because in the last 7 years or so—and before that, even—the median amount of JavaScript we serve has increased. Half the sites you visit today will send 375 KB or less of JavaScript. The other half will send more.
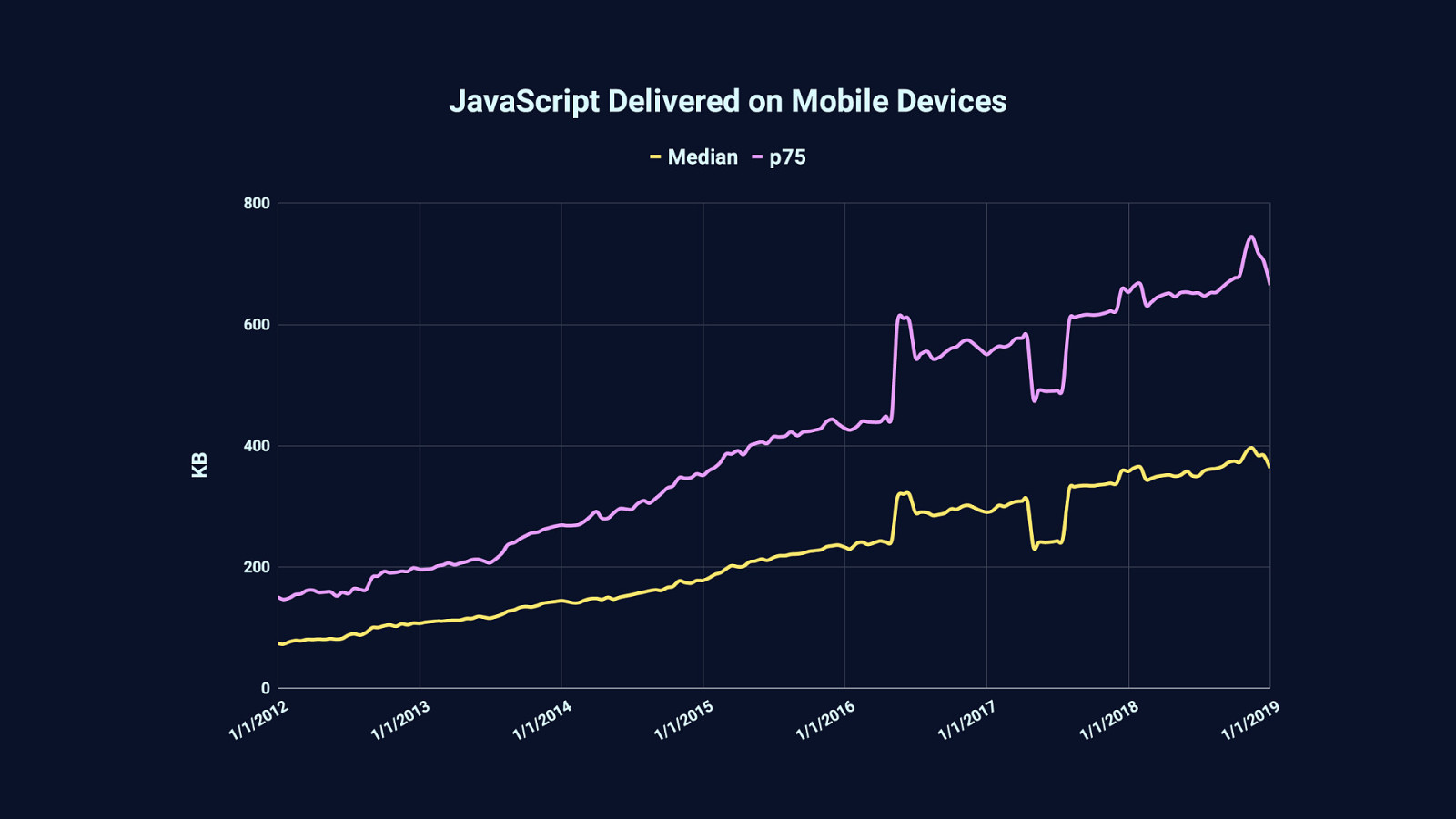
Sometimes a lot more. 25% of websites will send around 650 KB or more…
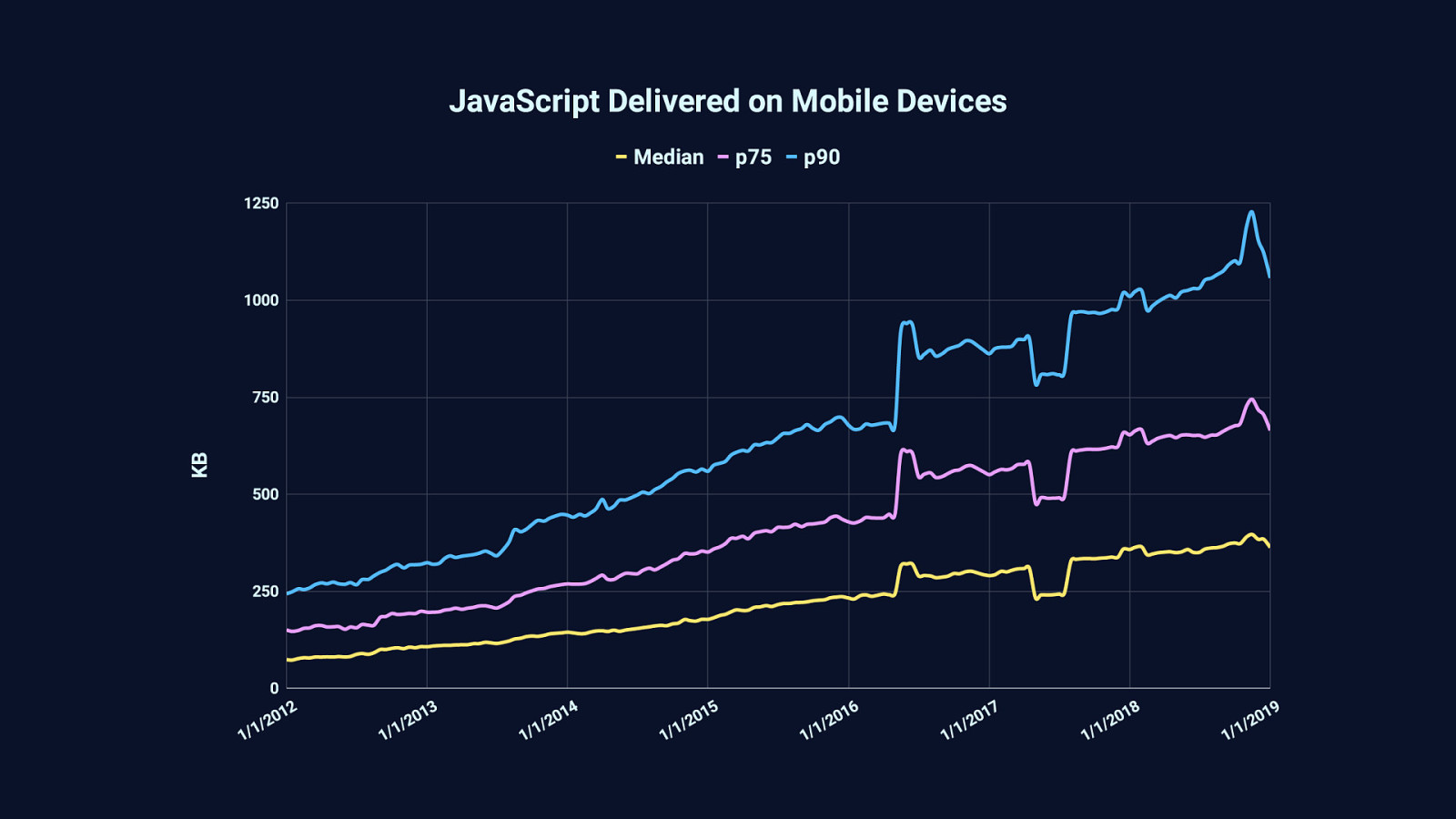
…and 10% of websites will serve one megabyte or more of compressed JavaScript. These graphs are generated from data provided by the HTTP Archive, which among other things, tracks the transfer size of JavaScript—which is usually compressed… …and while compression is essential to loading performance, it doesn’t change one stubborn fact about runtime performance.

Which is that, on arrival, one megabyte of compressed JavaScript gets decompressed to three megabytes of JavaScript which browsers must parse, compile, and execute.

If you’re using high-end devices on low latency and high bandwidth connections, you won’t notice this on all but the slowest websites. This is the bubble we tend to live in. Unless you’re performance-minded, you’re not likely to take notice of this problem until it affects you personally. That’s just human behavior.

But on median mobile hardware—such as this affordable, but slower Moto G4 Android phone—chewing through megabytes of JavaScript makes for a frustrating experience.
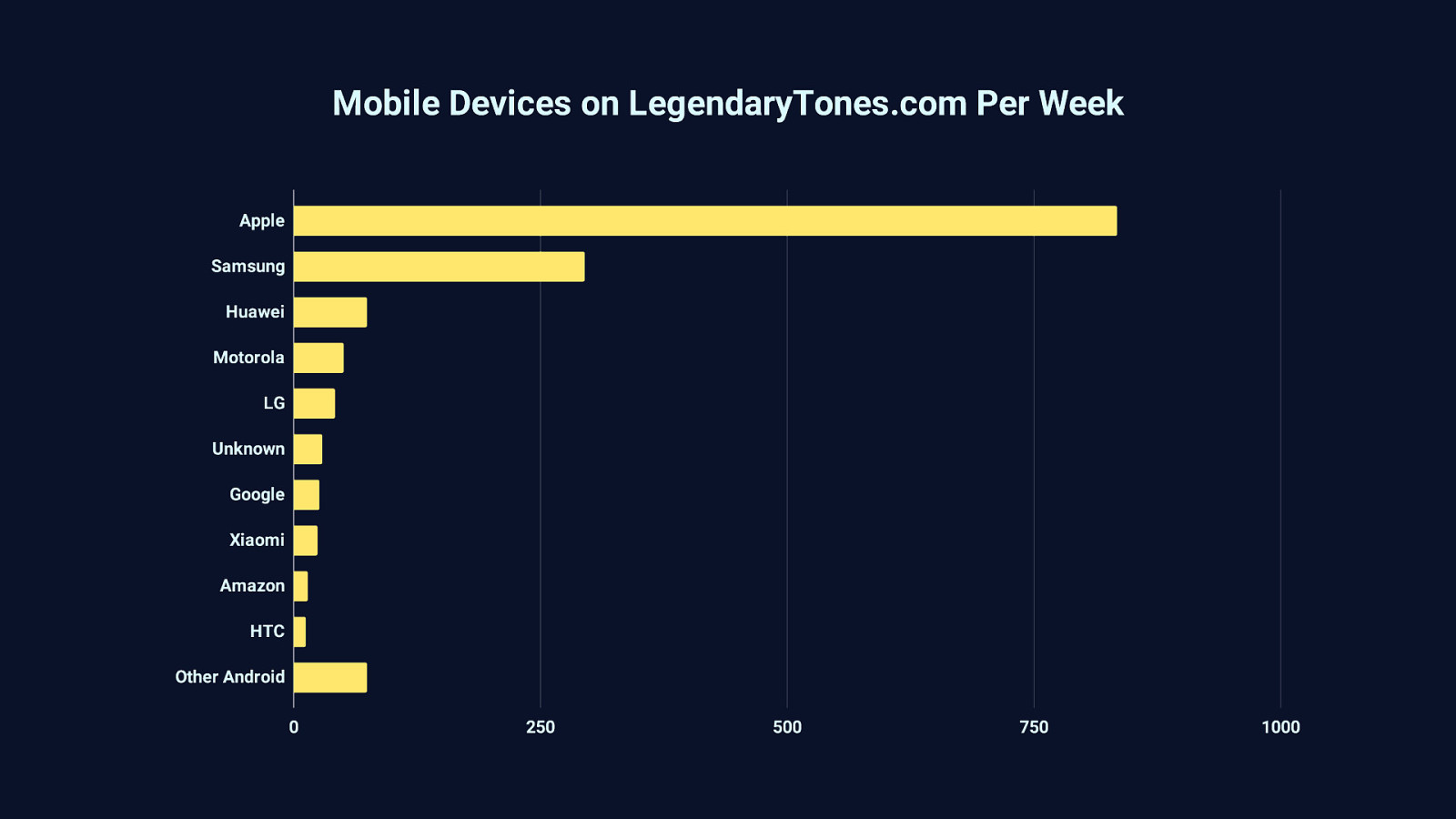
It’s easy to brush aside the long tail of devices like that Moto G4 and assume that those who use what we make are on high end devices—and a good chunk of them may well be. But the bigger picture of the devices accessing the web is different than the assumptions we tend to make. For example, take this graph based on analytics from a blog I host for a friend on guitars and related accessories. This site receives significant traffic from mobile devices from all over the world, with a very long tail of strange devices I couldn’t fit individually on this graph.
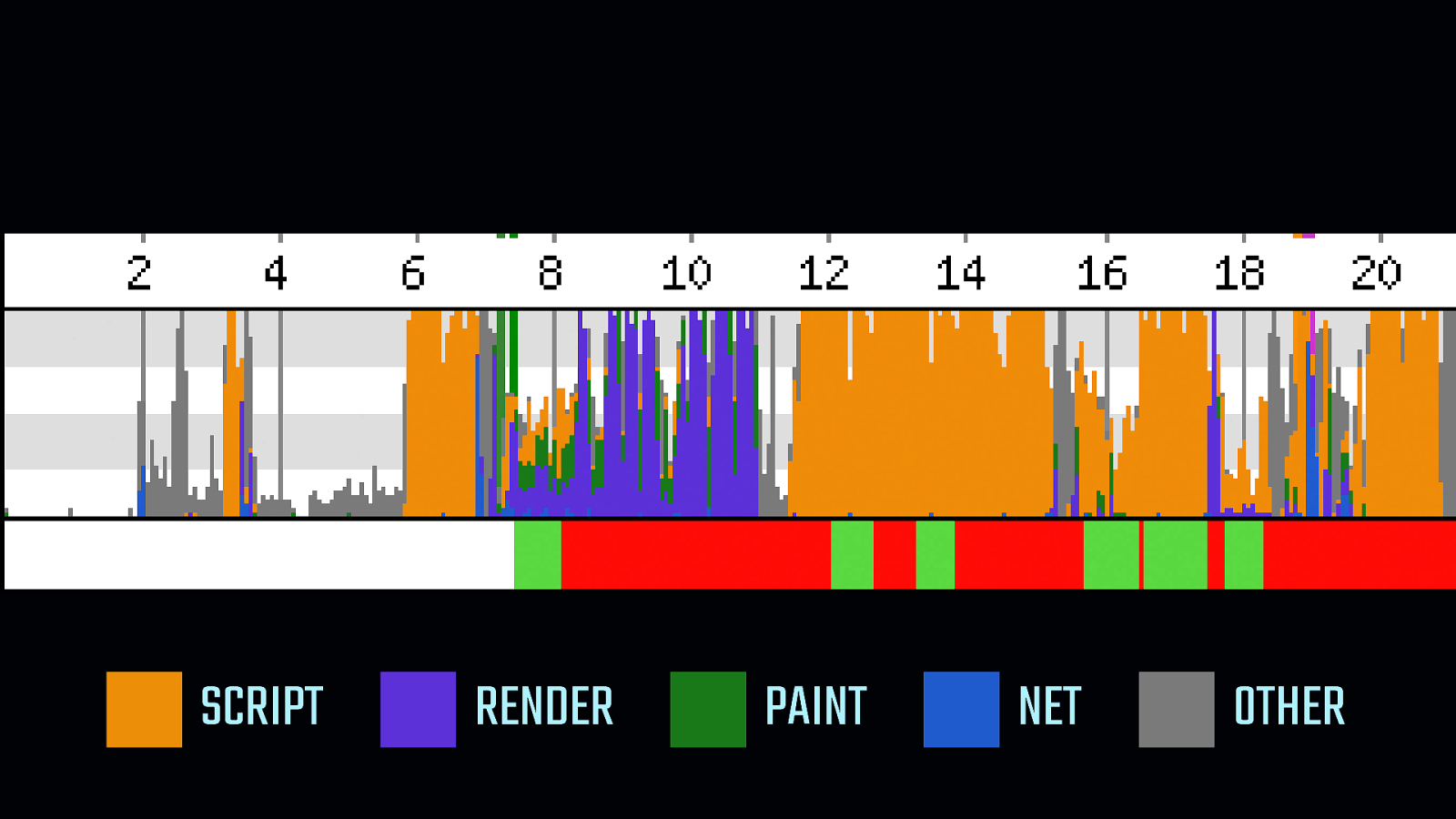
At the bottom of this WebPageTest timeline is the main thread activity indicator. When it’s green, the user is able to interact with the page… …when it’s red, the device is unable to do anything. The main thread is totally occupied, browser FPS has cratered, and users are waiting for a hanging device to respond. The device is unusable for 2, 4, sometimes even 6 seconds at a time. Pair that with a slow network, and you can imagine how tiresome the web becomes to use on median hardware. We are not building experiences that can work in all the places they might need to.
Understanding constraints is key to writing good software. Some of the best video games ever made were one megabyte, sometimes far less. These people had vision. They understood the constraints they needed to work within. But their constraints were fixed to the systems they produced games for. They developed content for people who all owned the exact same hardware. Our constraints are not fixed. They can be wildly different from person to person. In a way, that makes our job much more difficult than theirs. But that doesn’t mean we can’t make truly great experiences on the web that work for everyone, everywhere.

So let’s talk about how we can turn our sphexishness…

ANTI-SPHEXISHNESS

…not the frame.

It comes from an article by Eric Bailey about accessibility and UX. The implication of “paint the picture, not the frame” is that we should focus on what we want our websites to do for people…

…and that we should not subvert expectations by changing externally consistent behaviors. External consistency is something we expect in many facets of our lives. An example of when external consistency is disrupted might be a website that changes the appearance of scrollbar in a way that isn’t consistent with a person’s expectations; a decision which may impede people in ways we didn’t anticipate. Or, perhaps more importantly, how when we fail to use semantic HTML we create experiences that are difficult to use for those who rely on assistive technology.

“Paint the picture, not the frame” is a wry way of saying that we shouldn’t reinvent things things the browser already does well—like buttons or forms. More often than not, those things just need to be used correctly—or used in the first place.
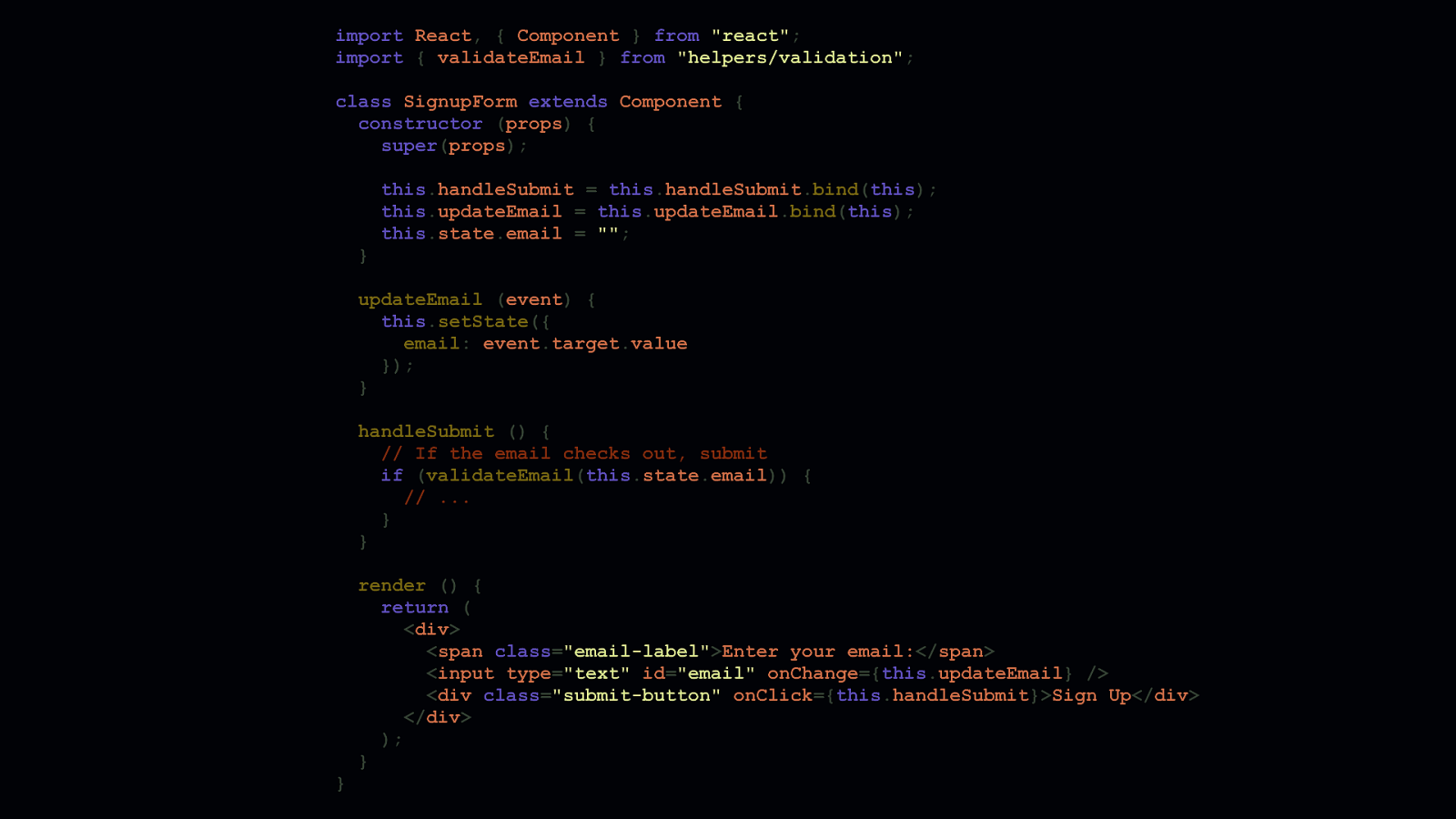
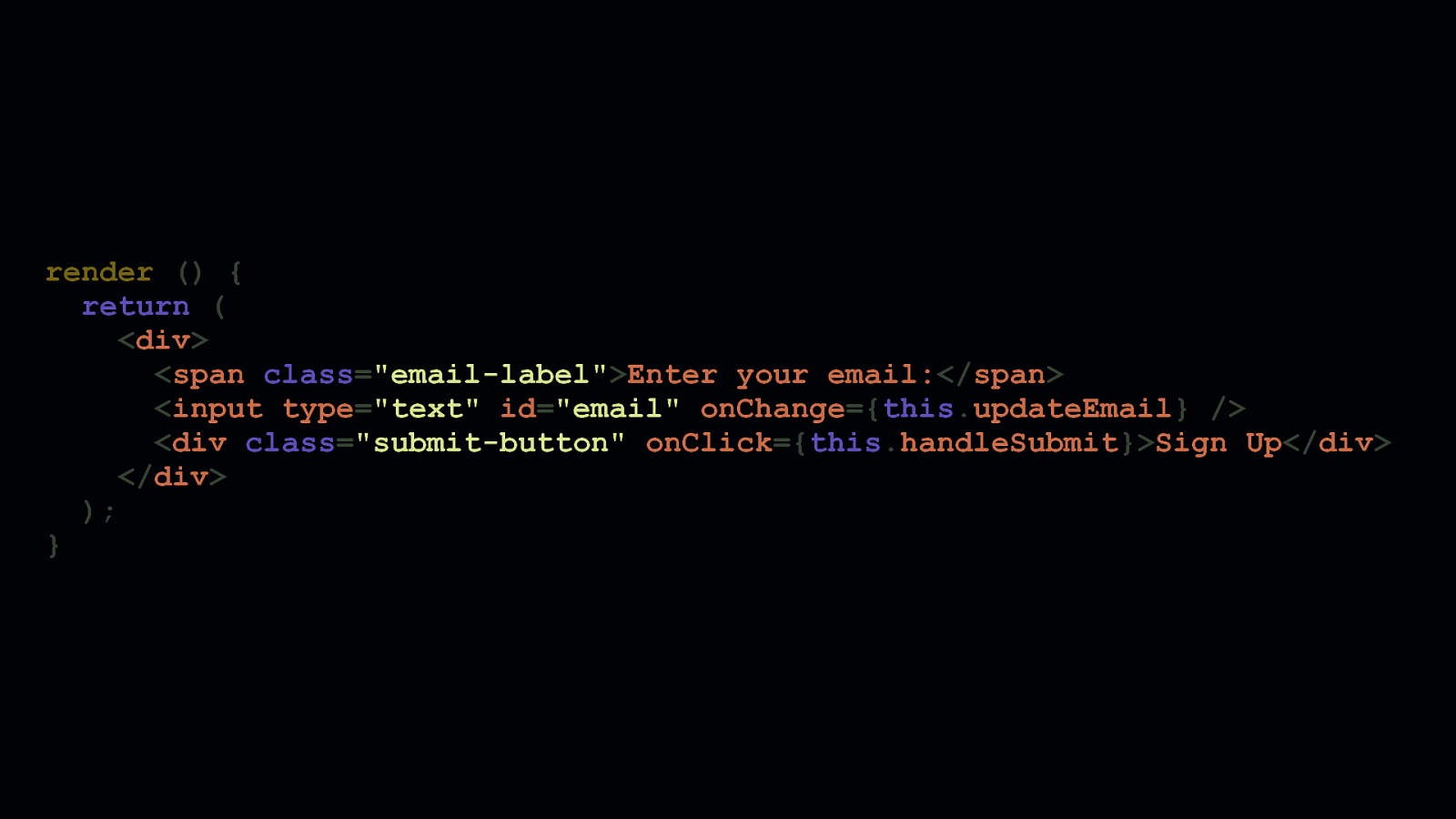
render () { return ( <div> <span class=”email-label”>Enter your email:</span> <input type=”text” id=”email” onChange={this.updateEmail} /> <div class=”submit-button” onClick={this.handleSubmit}>Sign Up</div> </div> ); }
Let’s take this example email signup React component. The email signup form is a stateful component that has one field, a label for that field, and a submit button. All contained in one <div>. I’m sure you have opinions on what’s wrong with this code, but the solution doesn’t require more JavaScript. It requires less. Let’s dig in and take a look at the <form> JSX…
There are three big things wrong here: - One, a form is not a form unless it uses a <form> tag. - <div>s are not intrinsically flawed, they lack semantic meaning by design. They’re developer conveniences for structuring markup. - But this is a form. Forms should always use <form> tags. - Two, when we label form fields, a <label> element should be used with aforattribute that corresponds to anidon an<input>element. - This lets assistive technologies know that a label corresponds to a specific input. - Tying labels to inputs with semantic HTML helps all people interact better with forms. - Three, while<div>s can be coded and styled to behave and look like buttons, doing so robs a button of any semantic meaning it would otherwise have if it was just a<button>element. - And! Here’s a bonus: a<button>element’s default behavior within a<form>` element is to submit that form. This makes for a more fault-tolerant solution for when—not if—JavaScript fails to run. Now let’s take a look at this JSX if it were refactored to be more accessible.
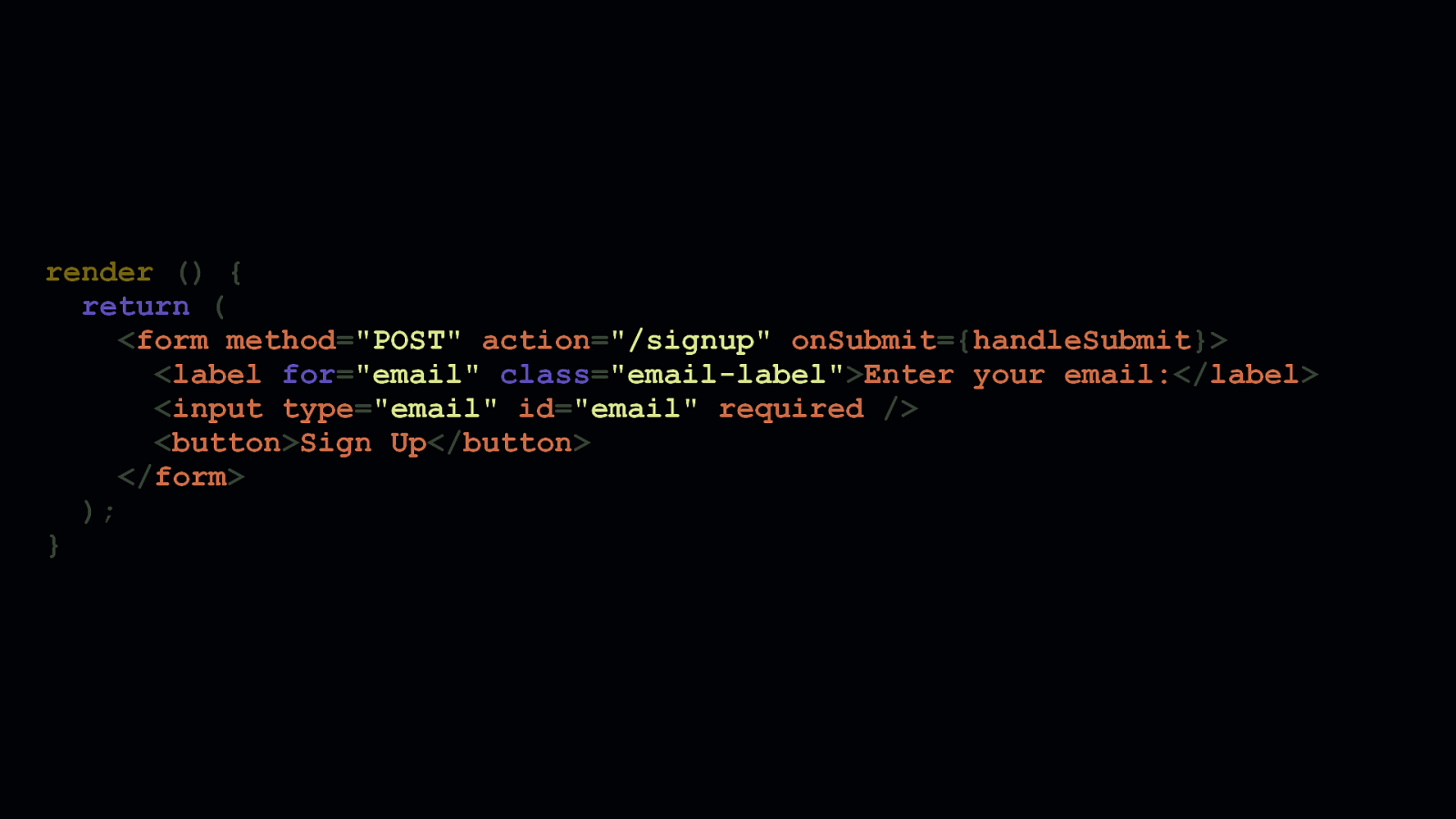
This is the refactored form JSX. Every part of it has semantic meaning assistive technologies can use. It will also continue to work if JavaScript is unavailable—assuming, of course, that the component is rendered on the server. Also note how the submit event handler has been moved from the <button>’s onClick’ event to the<form>’sonSubmitevent. This is helpful for when we want to intercept a form’ssubmitevent if we want to enhance this form’s behavior with client-side JavaScript. Additionally, we’ve also removed thevalidateEmailfunction, and used anemailinputtypein combination with arequired` attribute to leverage the browser’s own email field validation behavior.
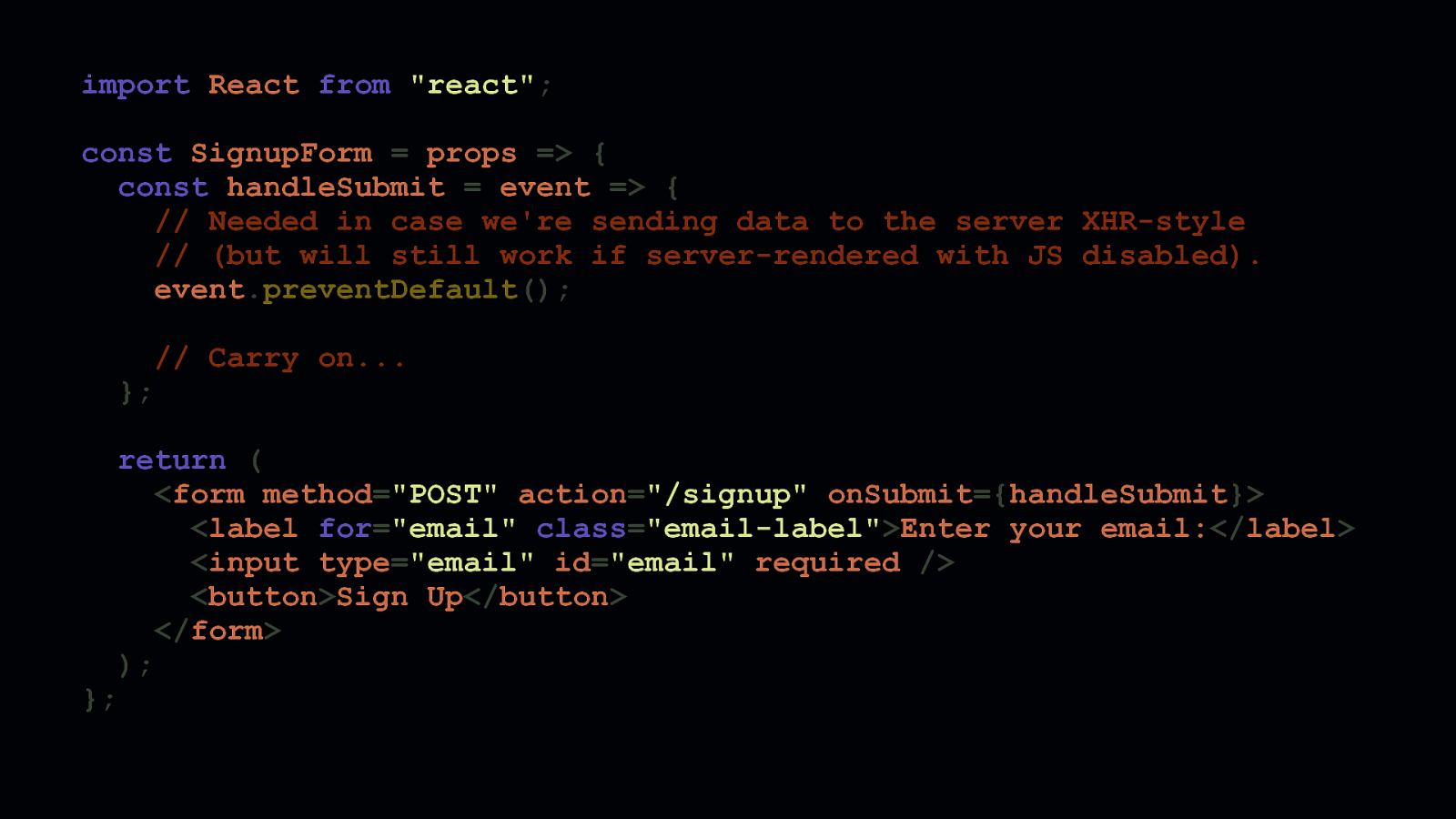
return ( <form method=”POST” action=”/signup” onSubmit={handleSubmit}> <label for=”email” class=”email-label”>Enter your email:</label> <input type=”email” id=”email” required /> <button>Sign Up</button> </form> );
Now, here’s the final component code in its entirety, which we’ve refactored from a stateful component to a stateless component. Because stateless components don’t extend React’s Component class, the transpiled and optimized output for this component will be significantly smaller. Additionally, because email validation is now handled on the client, we can remove the JavaScript that once did that for us. The vast majority of browsers provide this functionality. Of course, we should always sanitize our inputs on the server. Don’t rely on the client alone to do this. Where possible, move validation logic to the server, rather than forcing the client to load code to do something the browser can already do.

Of course, external consistency and semantics aren’t strictly limited to HTML, CSS, and JavaScript. We expect browsers themselves to behave a certain way. One of the most common subversions of expected browser behaviors is the single page application—or SPA. As a disclaimer, my personal inclination is to avoid building sites as SPAs. This isn’t because I hate them, or don’t understand them, or don’t think they can even be beneficial. It’s just that, well, the navigation behavior they replace is one that browsers already do quite well. It’s a problem that’s been solved very thoughtfully—if synchronously. Loading a client-side router can be begging for trouble.

Furthermore, when we fail to send markup on the server, the content of the app is potentially inaccessible if—and sometimes when—JavaScript fails to run.
And then, if components are attached to server side markup—a process known as client-side hydration—people receive a progressively enhanced experience. That gives us freedom to try different things. For example, perhaps only the authenticated part of an app can be a single page application. Or, you could design your application so that people could opt into client-side routing, ensuring it only happens if they want it to.


To address the possibility of wasted data, the Google Chrome team offers a very small library for prefetching pages as they scroll into the viewport. It only does so when the browser main thread is idle, if network quality is good, and if the user hasn’t stated a preference for reduced data usage using Chrome’s data saver feature.
If that’s still too risky, one solution I’ve come up with is a very small script called dnstradamus, which prefetches DNS information for outbound links as they scroll into the viewport. It’s not as effective as link prefetching. But it is less risky since DNS lookups are fairly small. For example, Cloudflare’s public DNS resolver issues request packets that are under half a kilobyte.

Most lazy loaders are quite small. My own solution yall.js, for example, is roughly 1.5 kilobytes uncompressed. Though some alternatives can be quite a bit bigger.
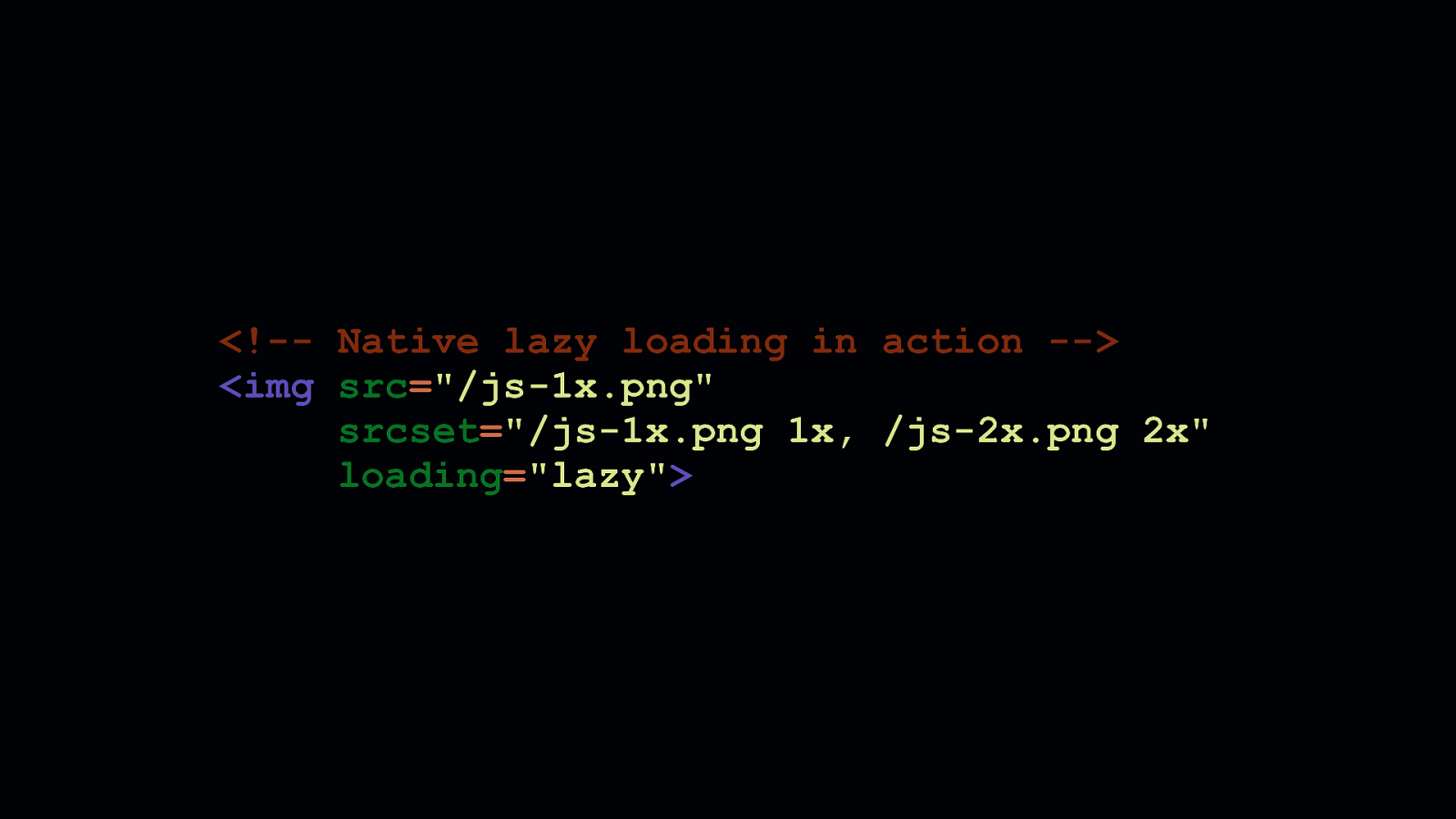
Regardless of size, no JavaScript solution can be as robust as a native browser solution. To wit, Chrome has recently shipped native lazy loading. Native lazy loading adds an additional loading attribute to <img> and <iframe> elements. It takes one of three values: auto, eager, and lazy. - auto does what Chrome did prior to the launch of native lazy loading. And, if browser heuristics are optimized in the future, they may intelligently defer the loading of assets depending on network conditions. - A setting of eager will ensure the content is loaded no matter what. - And a setting of lazy—shown here—ensures the content is loaded lazily. When the loading attribute is set to lazy for images, Chrome issues a range request for the first 2 KB of an image in order to render a placeholder. Then the content is loaded in full as it nears the viewport.
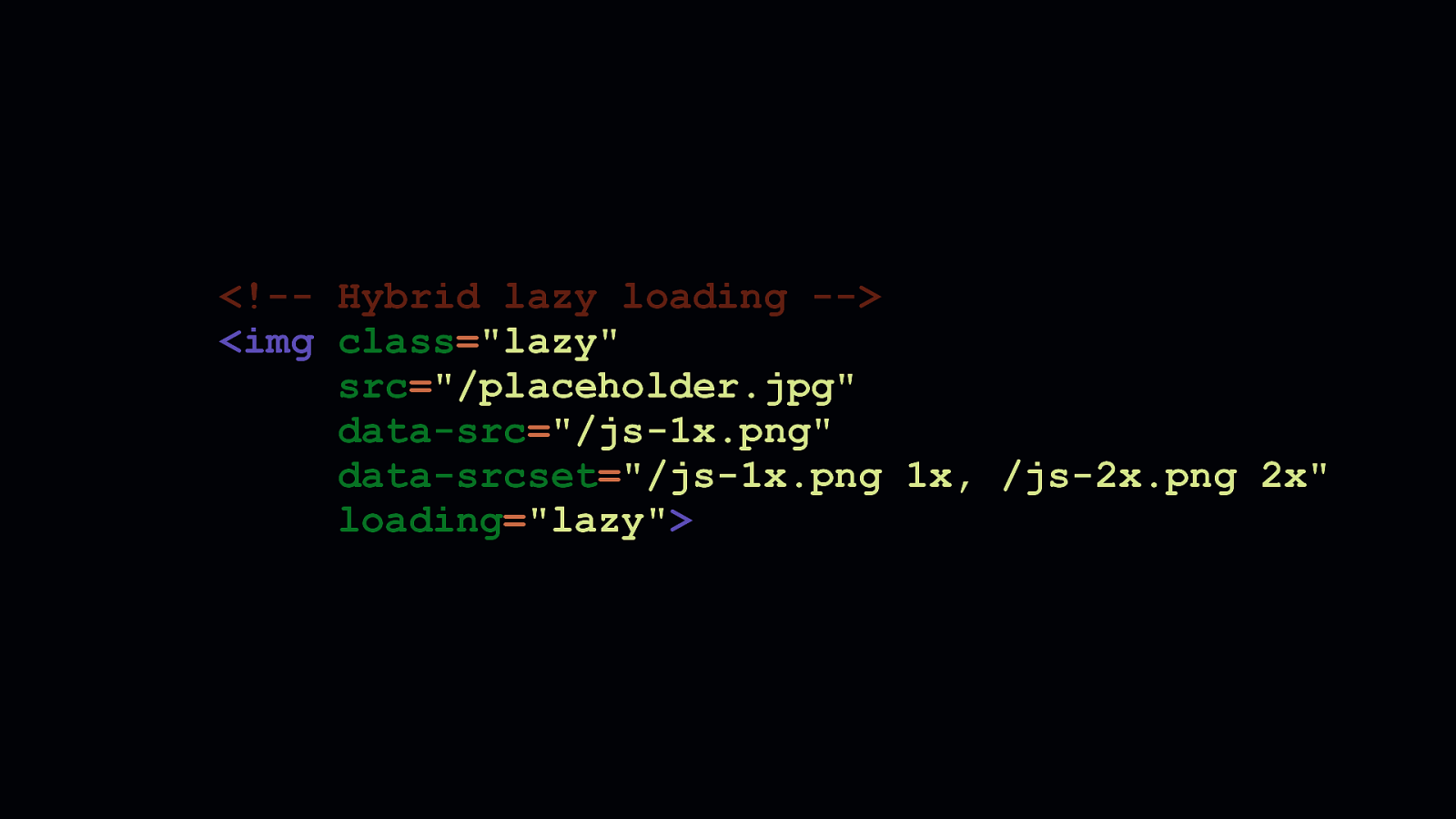
Because not every browser supports this, some work is needed to ensure all browsers receive a similar experience. You could conclude that only browsers which support native lazy loading should receive that benefit, while others get a less enhanced, but still perfectly functional experience. That’s progressive enhancement at its core. And it’s a fine decision. But, you may already be lazy loading images with JavaScript. In that case, you’ll want to ensure that the benefits of lazy loading are still extended to everyone. This markup shows how the common data attribute pattern used by many JavaScript lazy loading solutions can coexist in the same element with the loading attribute. Unfortunately, in this case, the placeholder will be lazy loaded. Not the final image sources we expect.
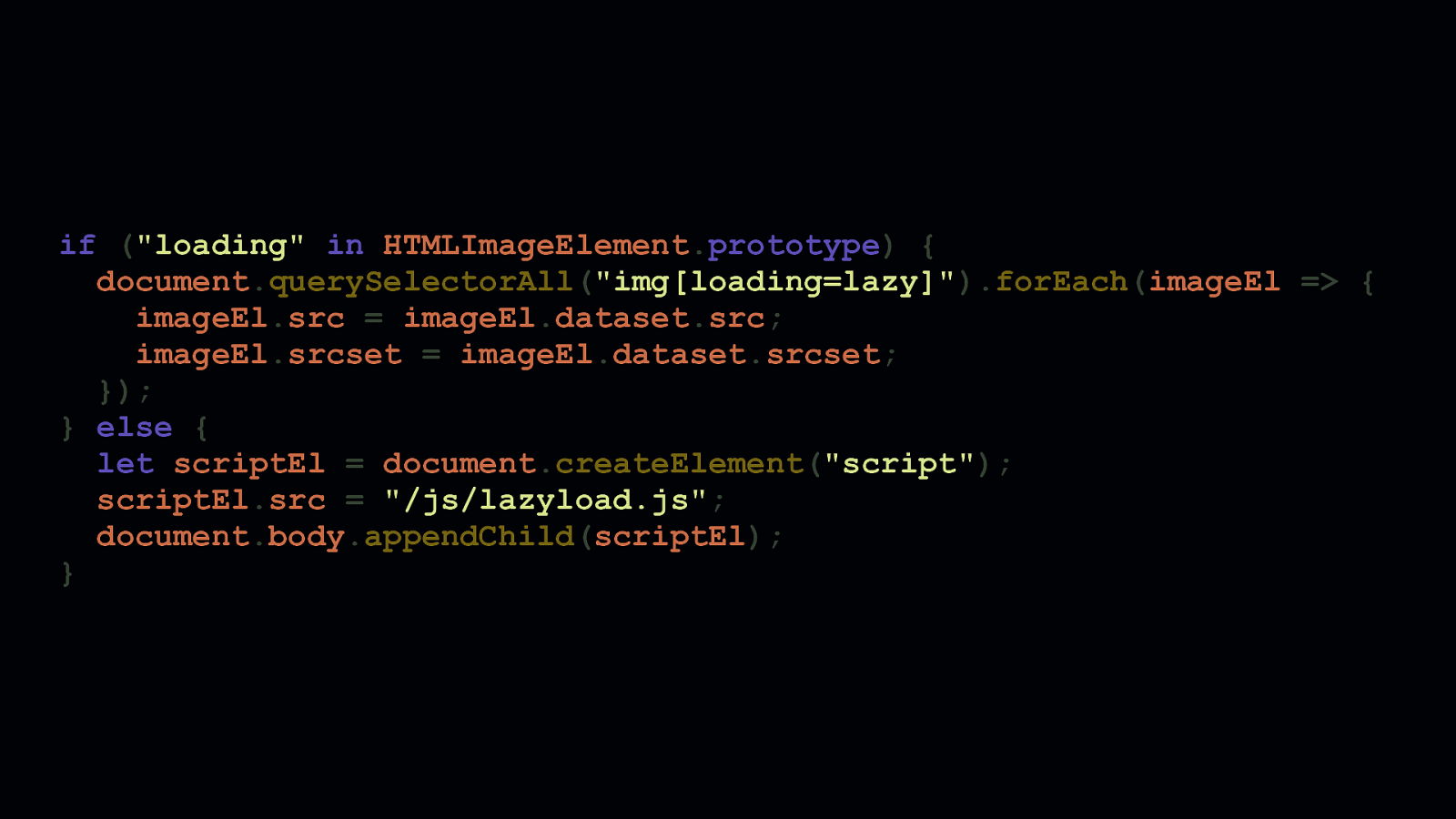
Feature checking is the way to go here. By checking the HTMLImageElement object’s prototype for the loading attribute, we can decide what we want to do if native lazy loading is a thing we can use—or if it’s not. If we can use native lazy loading, we can find all image elements with a loading attribute value of lazy and immediately populate the proper src and/or srcset attributes with the final sources and let the browser take over. If we can’t use native lazy loading, we can fall back to a JavaScript lazy loading solution.
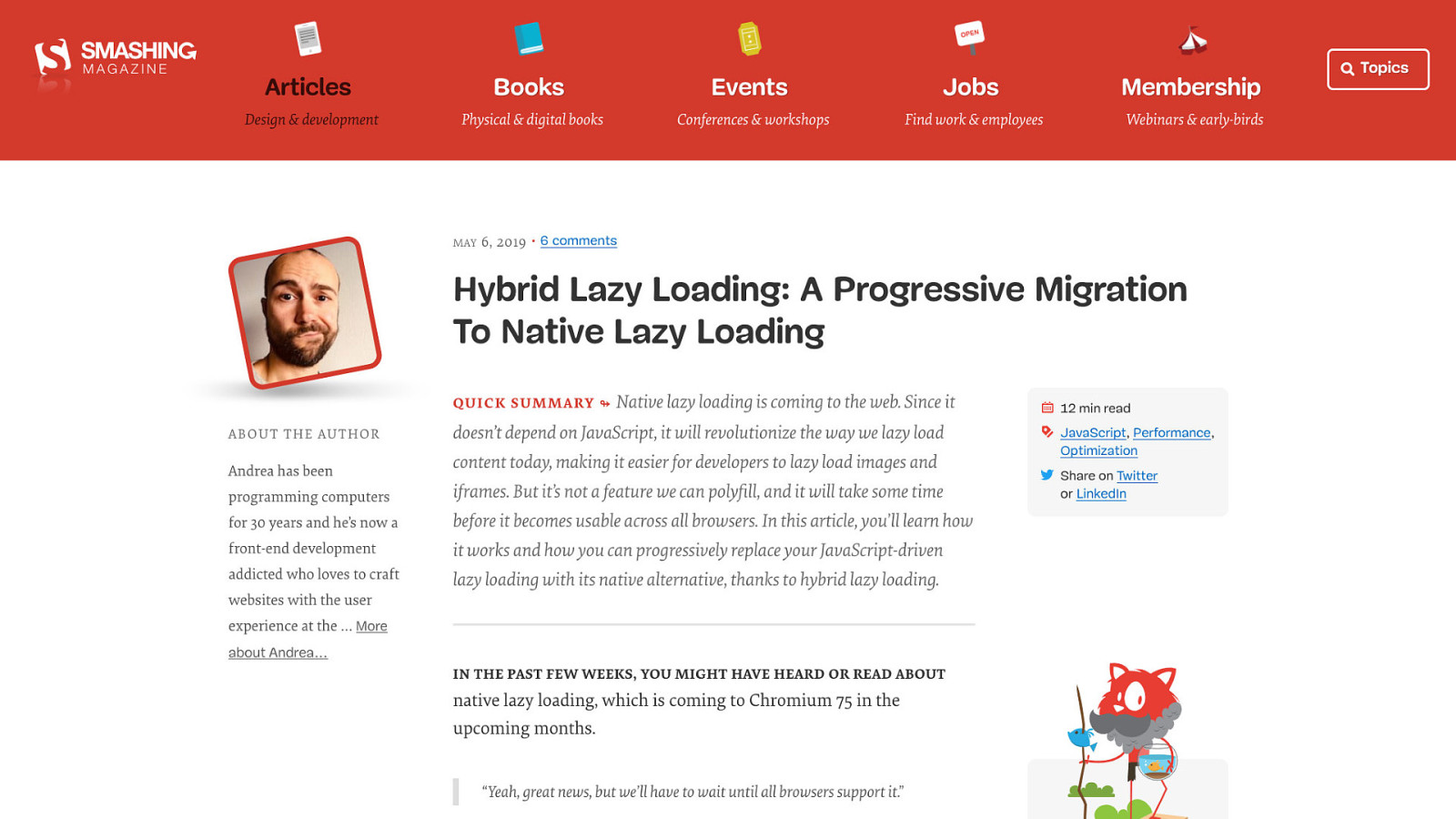
Of course, these things are always more complex than they first seem. Especially when you involve <picture> elements with multiple sources with various candidates for different screen sizes and pixel densities. Fortunately, this Smashing Magazine article on hybridized lazy loading by Andrea Verlicchi shows how you can manage both native and JavaScript lazy loading with care.

Now I may seem like I’m droning on and on about the stuff the browser gives us for free. But the point remains: The browser gives us a lot for free. Let’s use that free stuff whenever we can, so we can focus on the harder problems of web development.

Now, JavaScript isn’t to blame for the woes of the web. It’s how we use JavaScript, and how the responsible use of it starts with understanding one idea: [REVEAL TITLE CARD] - The tools are not infallible.

There’s one tool many of us depend on when we need the JavaScript we write to work everywhere. That tool is Babel. While we realize and appreciate everything Babel does for us, we sometimes fail to see the things it can do to harm performance. Babel is not something to idly slap into a project. We have to know how it works with the ES6 we write. We have to know how to configure best for our applications. While we benefit from Babel’s defaults, they may not always produce code that’s optimal for our constraints. These defaults are designed to be safe. Not necessarily the most optimal.

Those who use what we put on the web benefit from the broadened compatibility Babel provides. We can reach more people, and provide reasonably similar experiences regardless of the browsers people choose to use. But those users would also benefit if we could transpile less code. Because the way Babel transforms our source code sometimes adds more to our production code than we realize.

Let’s take this example logger function, which accepts a message and level parameter that gets passed to the console object. The second parameter specifies the log level. This corresponds to a console method like log, warn, or error. This parameter has a default of log.
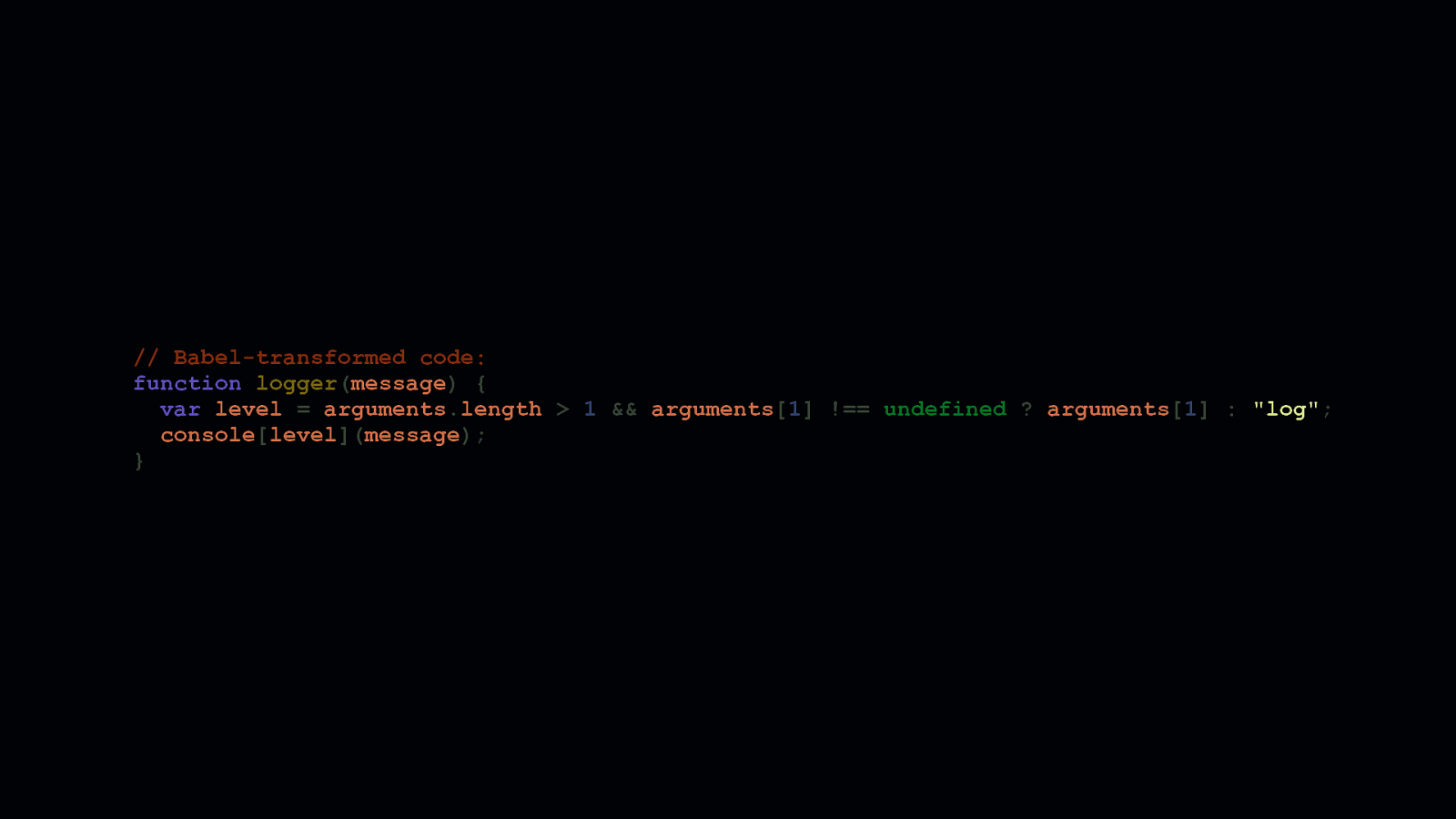
Default parameters are very convenient, but Babel often transforms them with excessive amounts of code. On top of that, this transform is repeated in every instance a default parameter is used. So if you use them a lot in your client side code, there’s an opportunity right there to ship less JavaScript. If we can’t avoid Babel altogether—and we can’t always—we should consider compensating for stuff like this. This is especially true if we’re writing libraries people install.
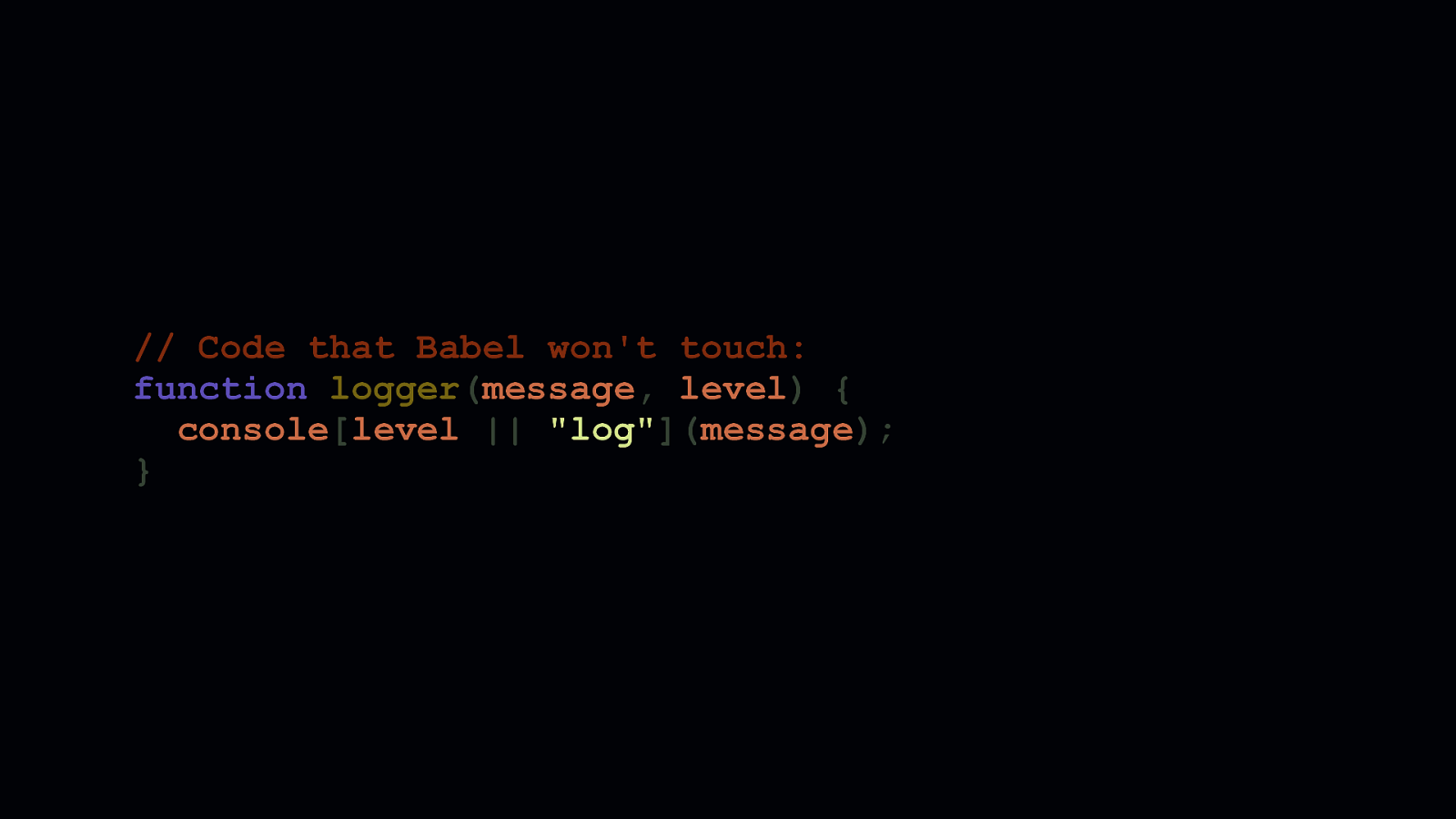
We can mitigate this transpilation cost by removing the default parameter, and replace it with an OR check. When a parameter is omitted at call time, the value of that parameter is undefined. When we want to assign a default to an “optional” parameter, we perform a check where the left side of the OR is the parameter itself, and the right side is the default. This means that if the parameter is not supplied, the right side of the OR condition is used. This isn’t bulletproof. If you have a parameter whose default is truthy or boolean true, you’ll need to perform a different kind of check, because if you supply a falsey or boolean false value, the “default” will always take precedence.
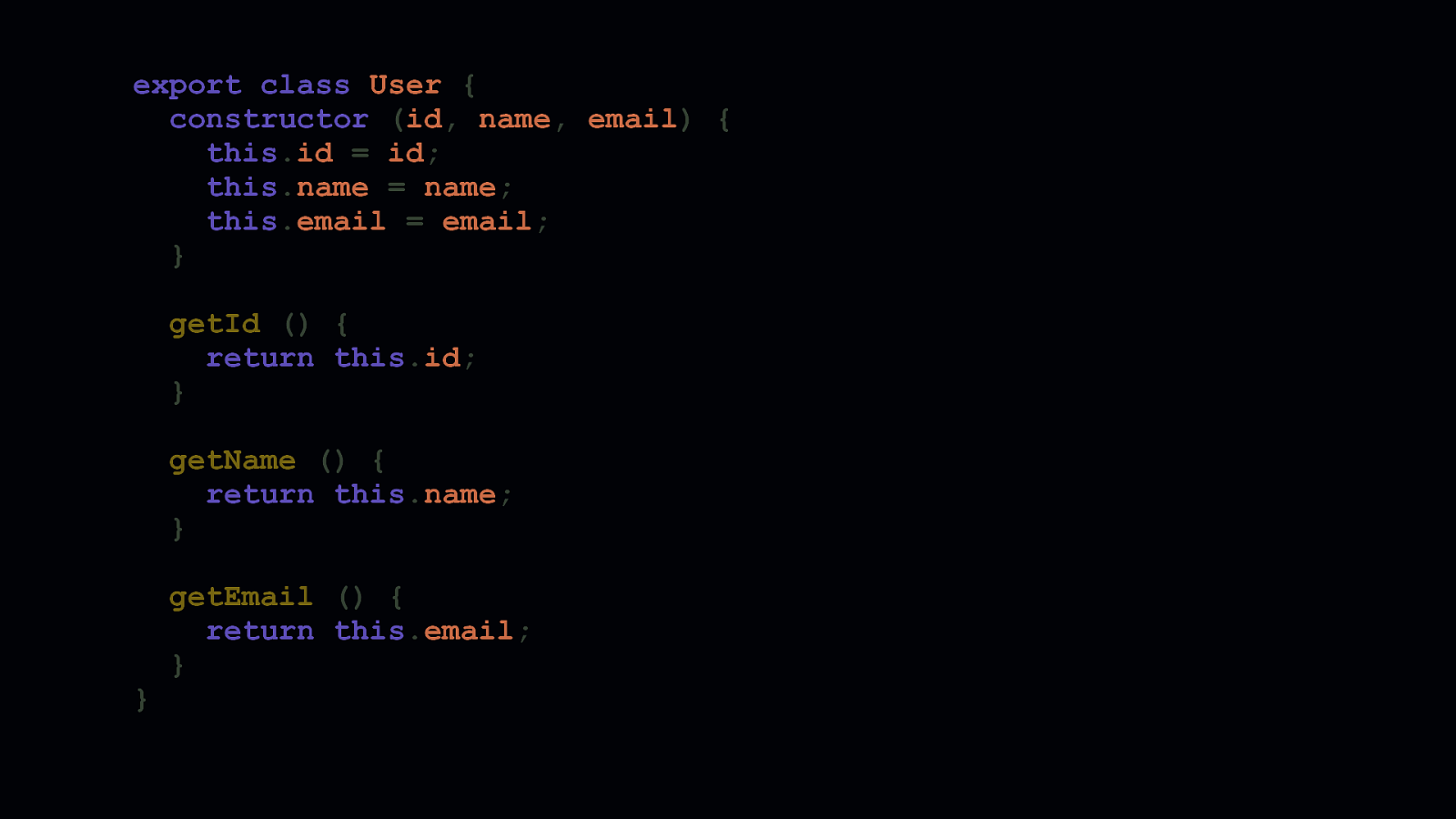
getEmail () { return this.email; } Default parameters are just one such feature that gets transpiled by Babel. In some environments, it transpiles ES6 classes, too. ES6 classes are great. It’s a reasonable amount of sugar to turn the prototype pattern into something that more closely resembles classes as they exist other languages.

But they have a cost. As you can see, Babel adds a lot to ensure that ES6 gets transformed into something that runs everywhere. If you want to mitigate this, you have options. - One, you could use the prototype pattern and write classes the way we used to before ES6 classes were a thing. - Two, you could use @babel/runtime in combination with @babel/plugin-transform-runtime to deduplicate the helpers Babel adds. - Or three, if your list of supported platforms can be limited to modern browsers, you could remove Babel altogether from your toolchain. If you can do this, it’s probably your best option. - However, if your app makes use of JSX, Babel isn’t so easily uninstalled.

How we write our ES6 isn’t the only thing to consider when we use Babel. We also need to know how to configure Babel itself. Suboptimal Babel configurations are tough, because even if you’re experienced in using it, there’s a lot to miss—or misunderstand.
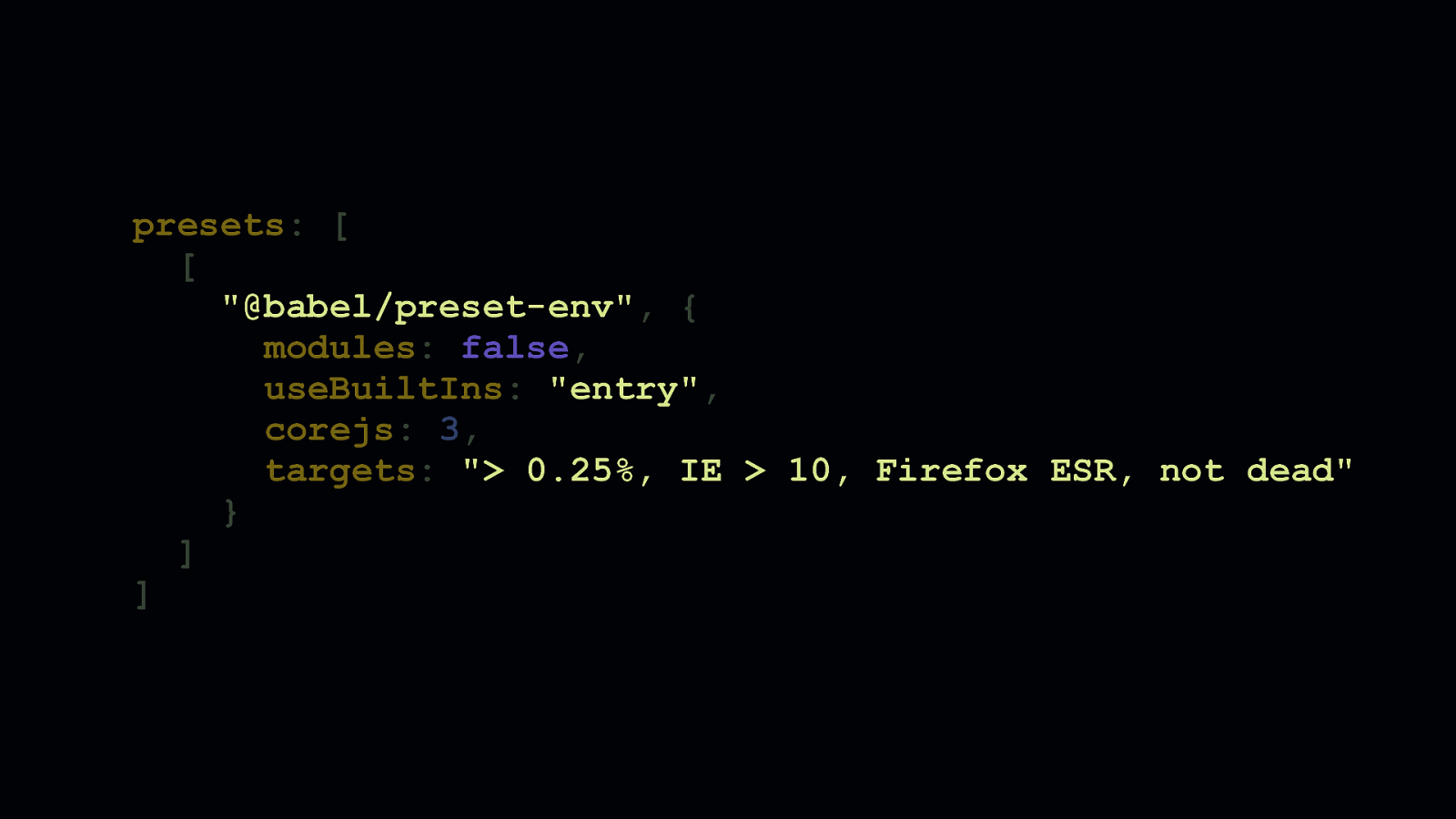
Polyfilling is something we use Babel a lot for. If you’re familiar with @babel/preset-env, this snippet may look familiar. However, it’s worth taking a second look at the useBuiltIns option, which we use in concert with core-js to polyfill features based on a browserslist query. When this option is set to "entry", we must ensure that core-js itself is an entry point in our app.

Doing this adds more polyfills to production code than we might need. Here, you can see that the main bundle of this example app is almost 117 KB. The majority of it being polyfills.
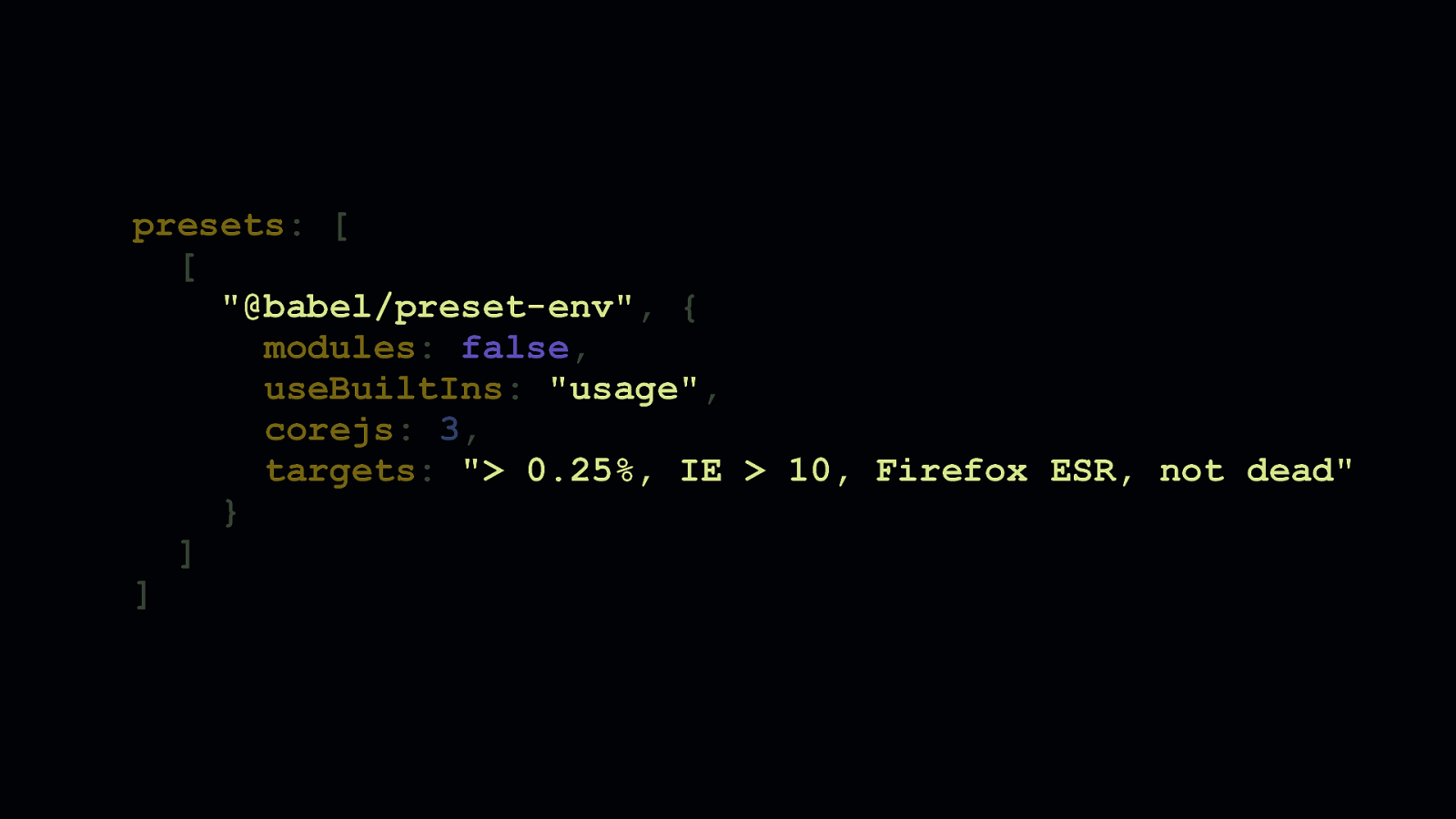
But, if we change the value of useBuiltIns from "entry" to "usage", we’re ensuring that Babel only adds polyfills based on the features we use. Depending on your project, this can have a profound effect on how much JavaScript you ship.
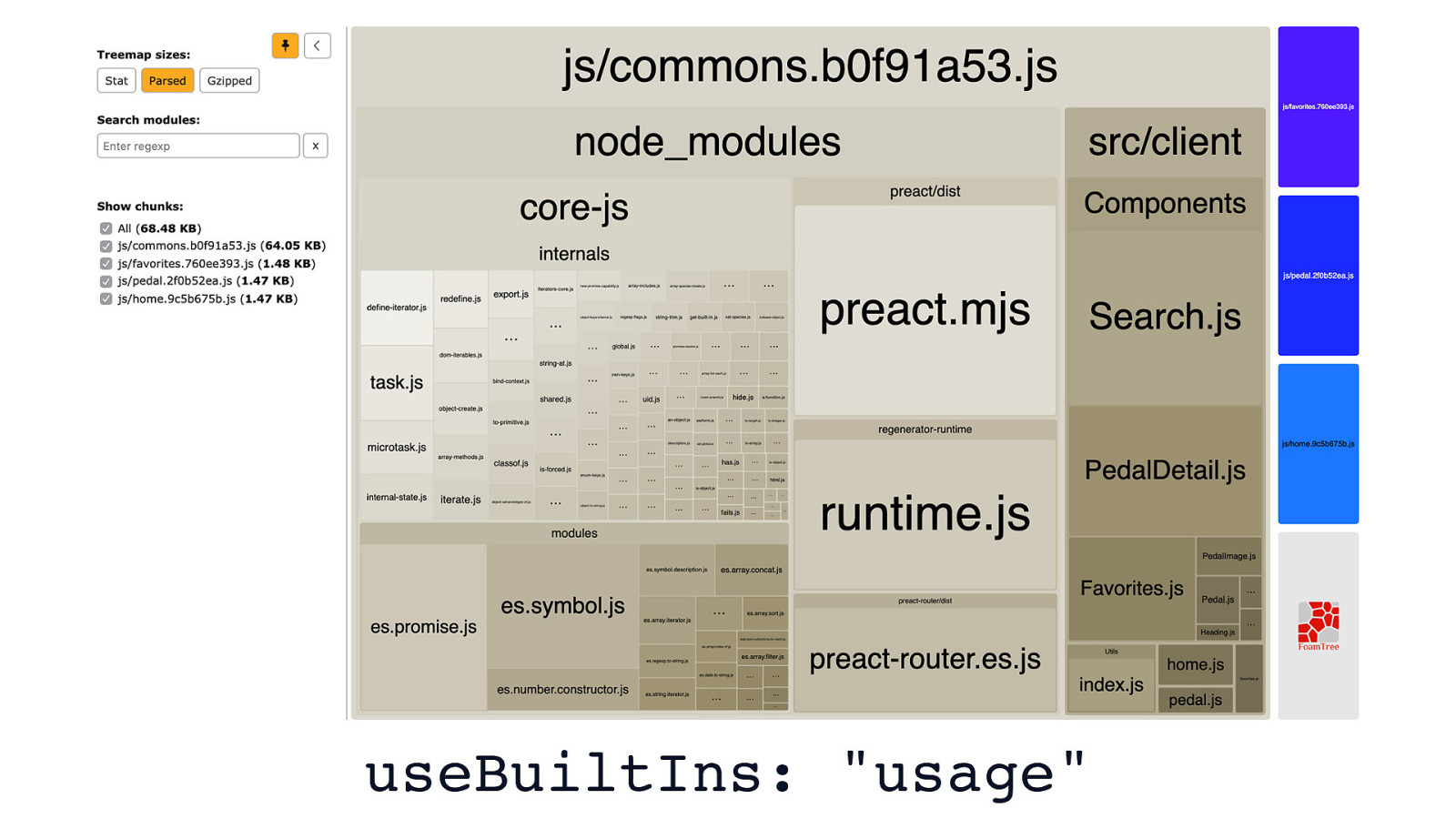
In the case of this example app, we go from roughly 117 KB of script to a much leaner 68.5 KB. That’s a 40% reduction, just from a quick config change.
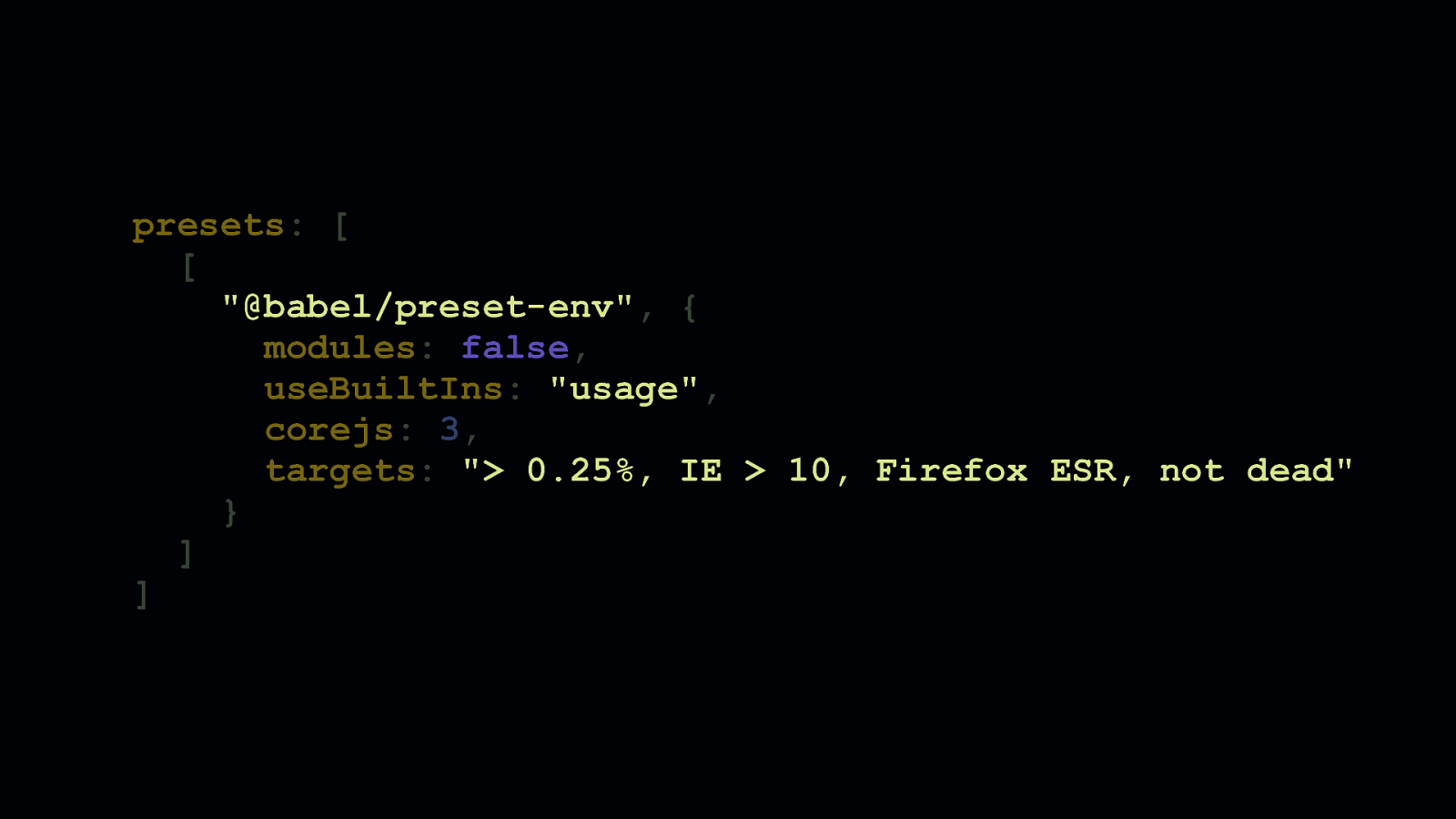
There’s another configuration flag in @babel/preset-env that deserves our attention which activates something called “loose mode”. “Loose mode” is when Babel takes your ES6 code and applies transforms to it that adhere less strictly to the ECMAScript standard. Because the transforms aren’t spec-compliant, they’re quite a bit smaller, and will still work in most situations.
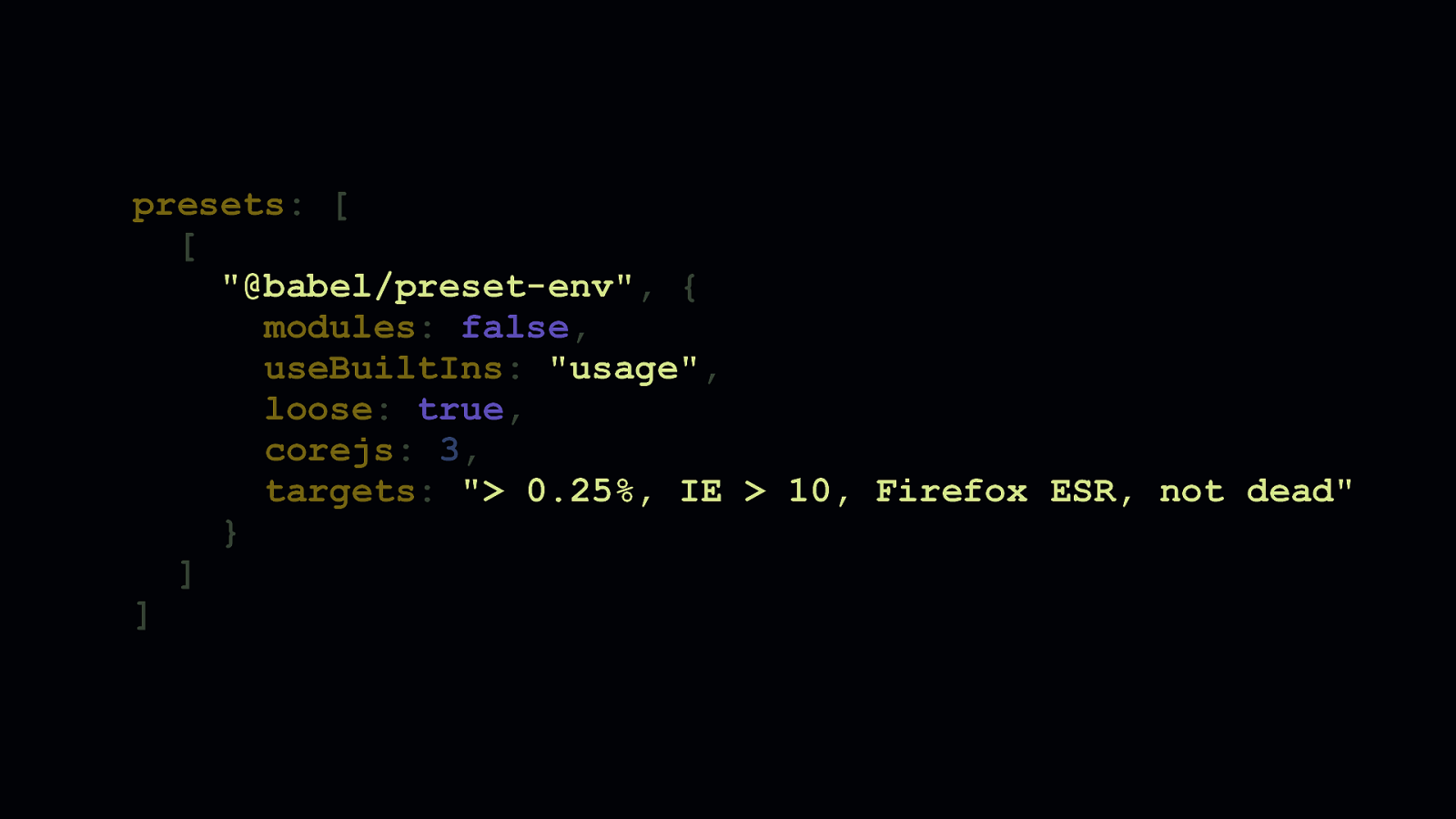
Loose transforms can be applied by enabling the “loose” flag, which is false by default.

Here’s an example app where loose transforms aren’t enabled. It’s pretty small as-is, but it could be smaller.

Now here’s that same app with loose transforms enabled. It’s 18% smaller. The app still works as before, although it’ll be a touch faster now.
However, loose mode isn’t bullet-proof. This post by Axel Rauschmeyer advises against loose transforms, but whether that advice pertains to your project depends. The criticism against loose mode is that if you move from transpiled ES6 code to untranspiled ES6 code later on, you could have issues. In my opinion, if the savings are worth it, you can always tackle this potential issue later on if you decide to drop Babel. Chances are good, though, that you’ll be using Babel for some time as JavaScript continues to evolve. And, if you’re using Babel to transform some non-standard syntax—such as JSX—you’re not likely to ever remove it from your toolchain.

Another way to serve less code to users involves a technique called “differential serving”. Differential serving is a method of serving one of two bundles to users: - Bundle 1 would be for those on legacy browsers. It’s the bundle you’re likely already serving which contains all the transforms and polyfills necessary for your code to work on those browsers. - Bundle 2 would be for those on modern, evergreen browsers. This bundle has little to no transforms or polyfills, depending on what language features you’re using. The benefit is that sites loaded on modern browsers will be able to be function with substantially less code.
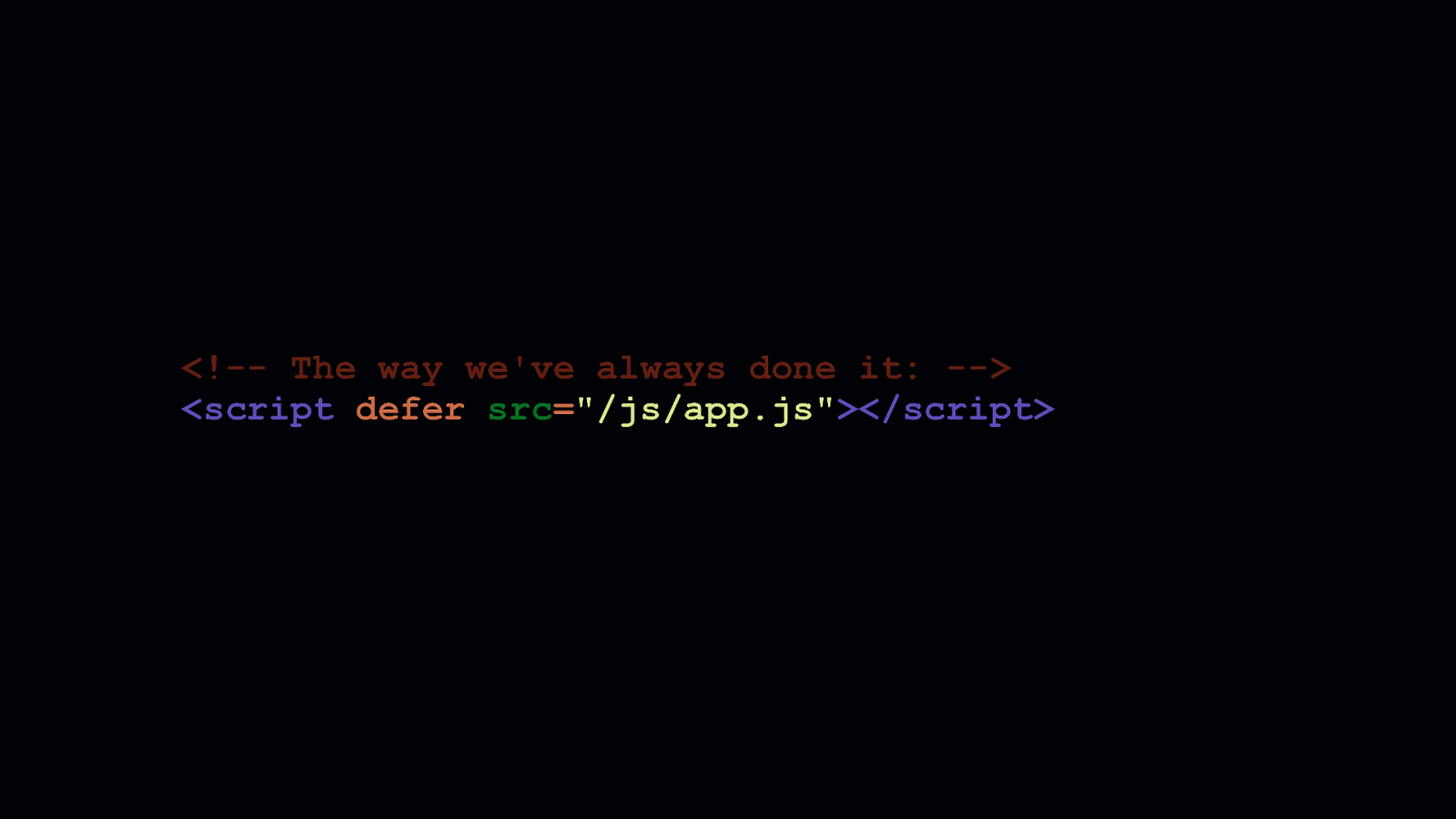
Of course, we need a way to load these separate bundles. What you see here is the way we’ve always loaded JavaScript.
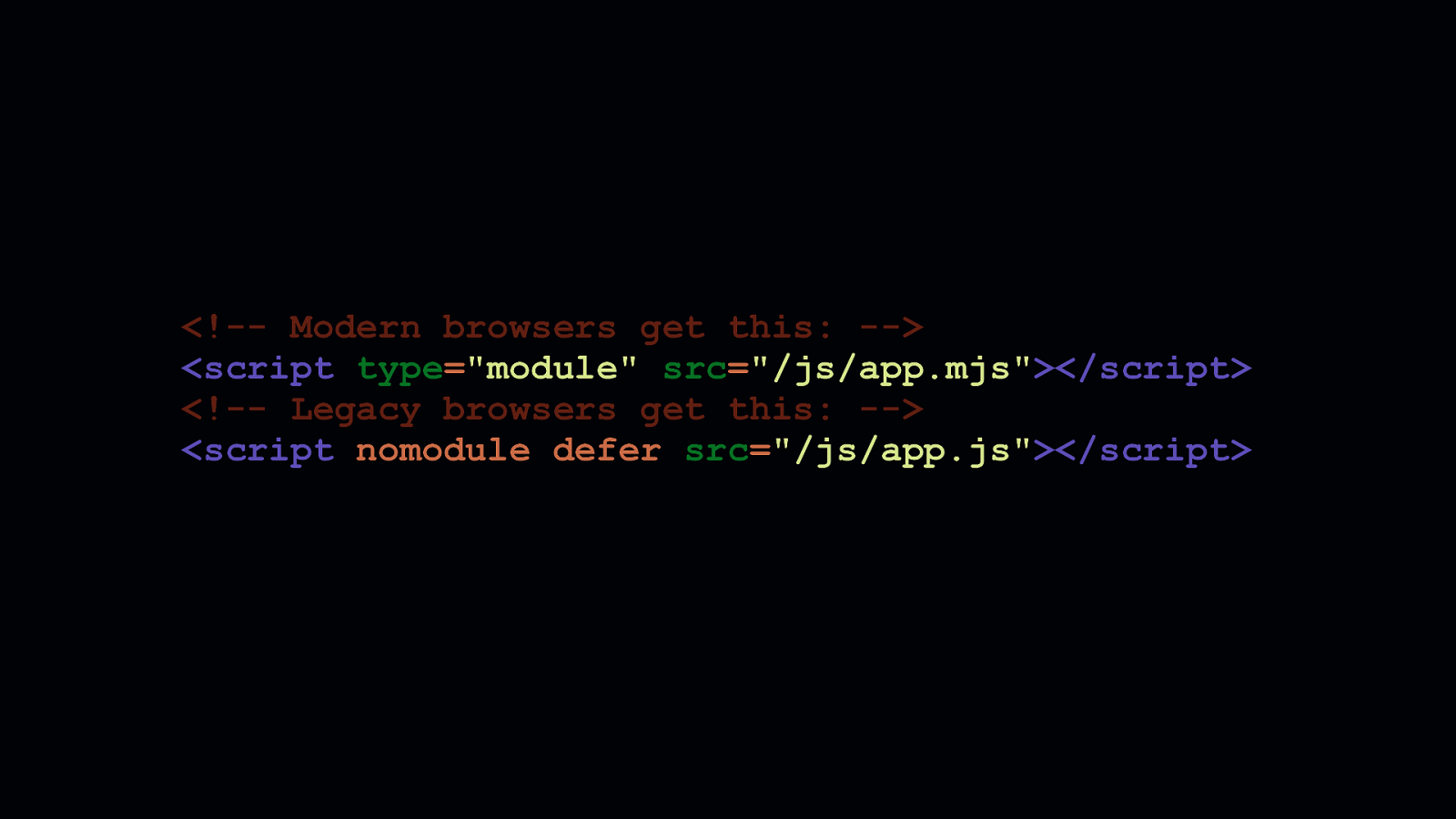
The pattern shown here is how we can differentially load scripts. The first <script> tag loads a bundle meant for modern browsers. - Adding type=module means this script will get picked up by modern browsers. - Because legacy browsers don’t understand that type attribute value, they’ll ignore it. The second <script > tag shows how we can load a bundle meant for legacy browsers. - The nomodule attribute isn’t understood by legacy browsers, so they’ll download this script anyway. - But, nomodule is understood by modern browsers, which will decline to download scripts requested by <script> elements bearing that attribute.
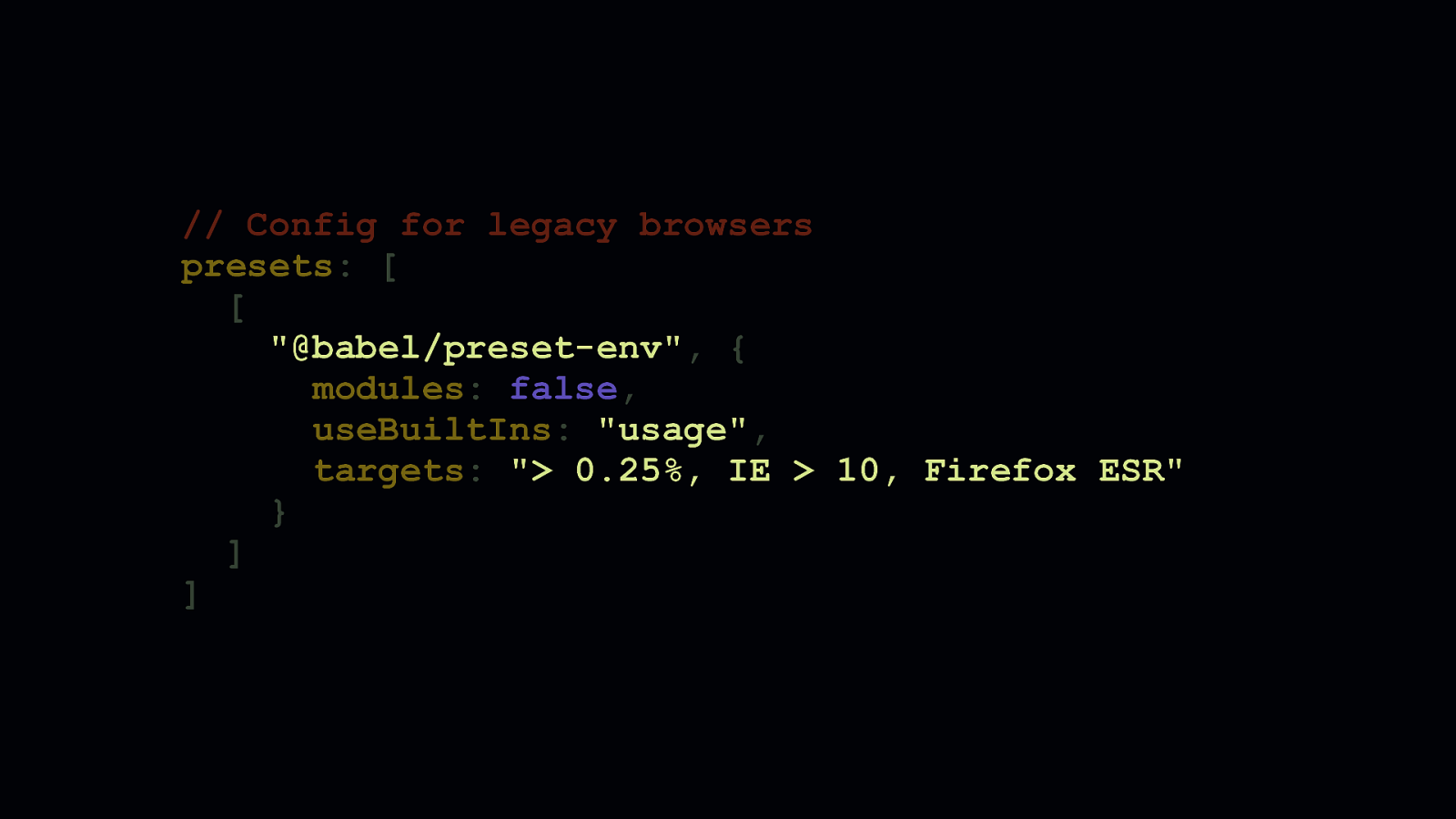
Configuring your toolchain to differentially serve code is another matter altogether, but doable. You need to create two separate Babel configurations: one for each bundle you generate. This Babel configuration here shows a typical config you’d see in a lot of projects: - We’re targeting older browsers… - …and we’ve specified useBuiltIns: “usage” to selectively add the polyfills we’ll need.
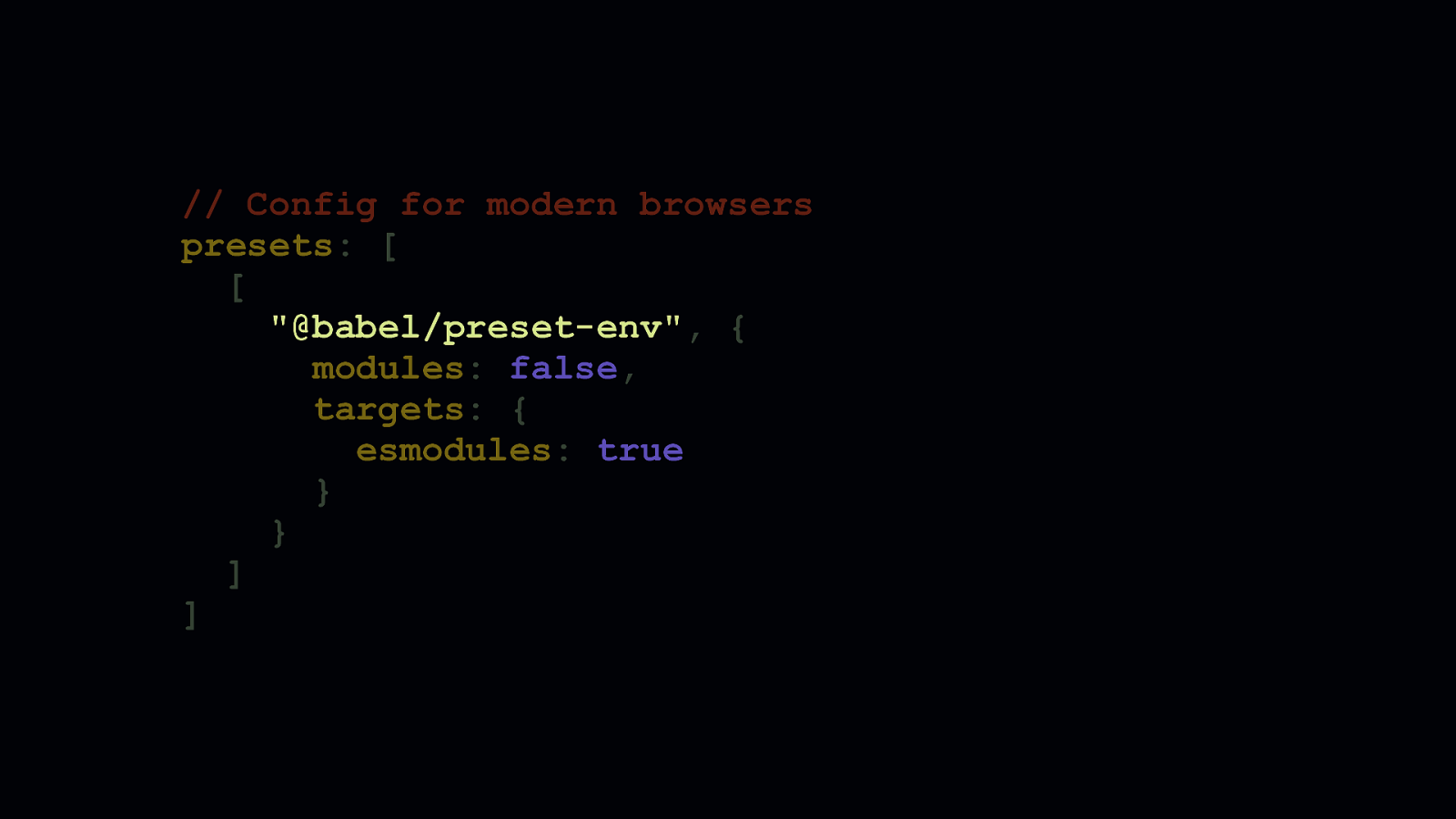
Now, this is a configuration for generating bundles for modern browsers. - You’ll notice that useBuiltIns is gone. That’s because this configuration would be for a project which needs no polyfills since modern browsers don’t need them. - Depending on the language features you use, you may need to retain useBuiltIns. You probably won’t need this most of the time. - We’ve removed the browserslist query, and instead supplied an option named esmodules set to ‘true’. - Under the hood, esmodules translates to a browserslist query which includes all browsers supporting ES6 modules. - This is convenient, because if a browser supports ES6 modules, it also supports other modern features, such as async/await, arrow functions, spread syntax, and so on.
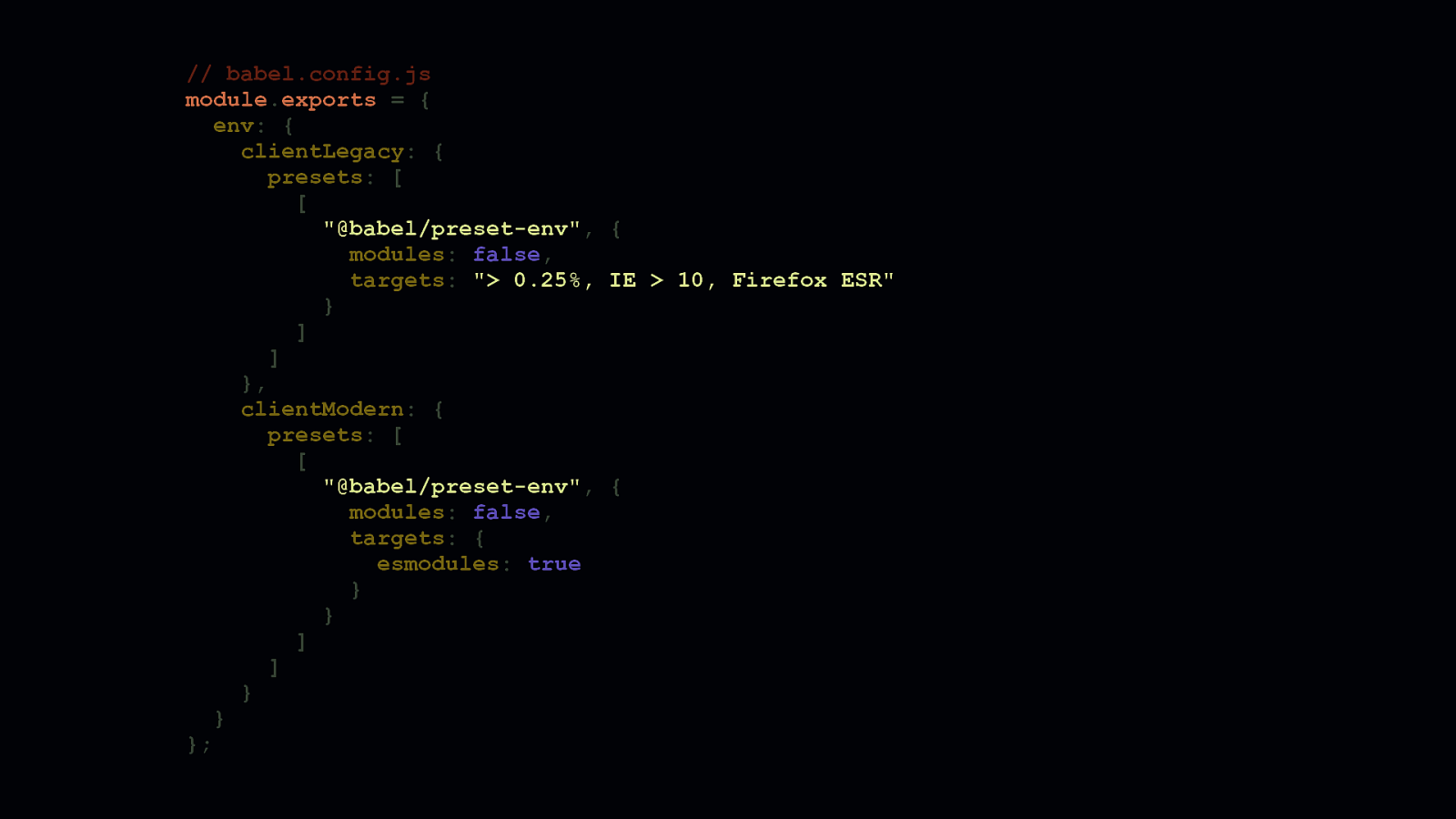
Now here’s how both configurations can live together. Babel allows us to group multiple configs under an env object. In our bundler configuration, we can point to these separate configs.
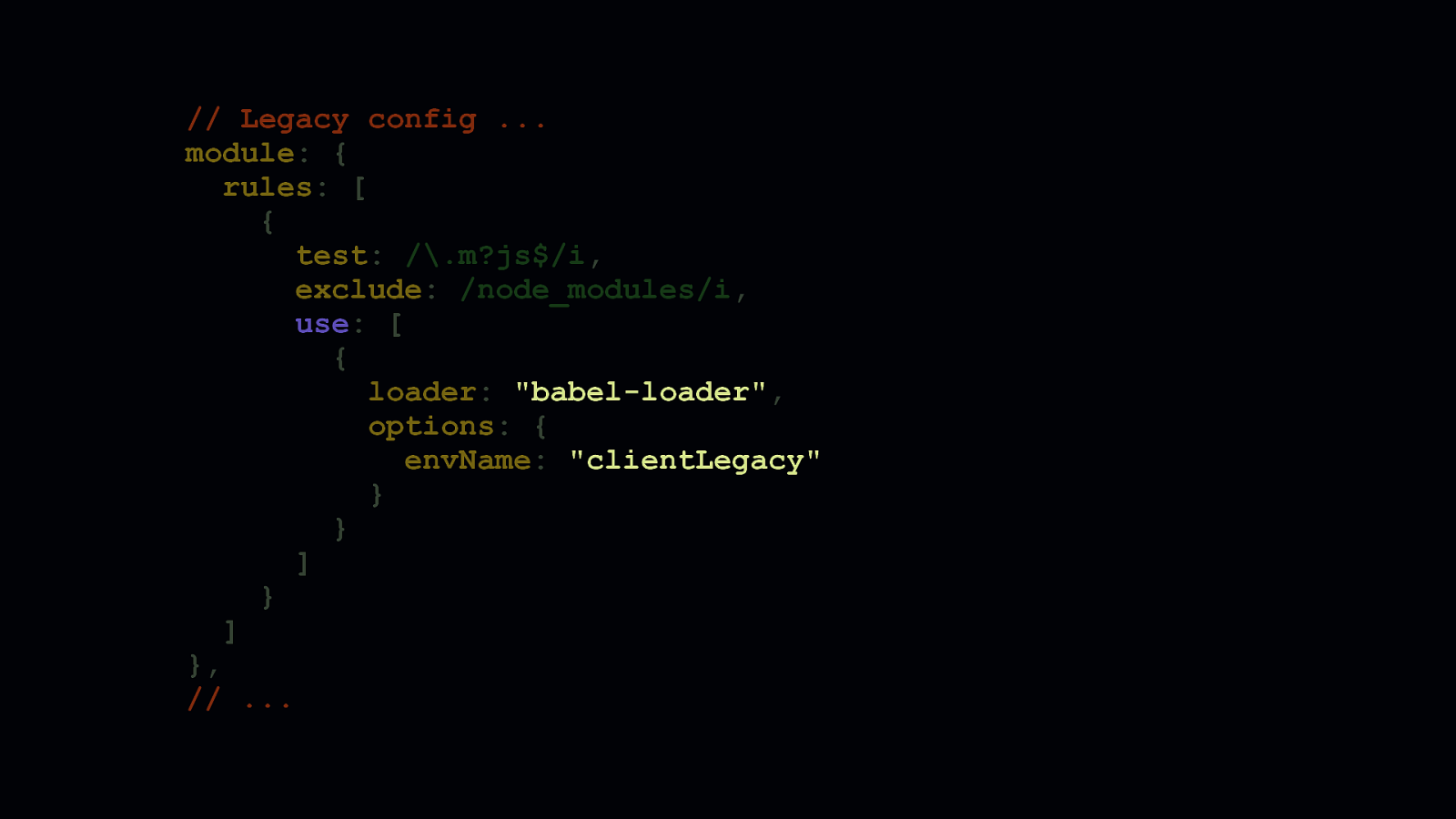
In webpack, this is probably how you use babel-loader to match script files to ensure they get processed by webpack. Note the envName setting. This points directly to a configuration in the env object in the Babel config from the previous slide. Then, using webpack’s multi-compiler mode which allows you to export multiple configuration objects in an array, you can create a wholly separate config to generate a modern version of your bundled code.
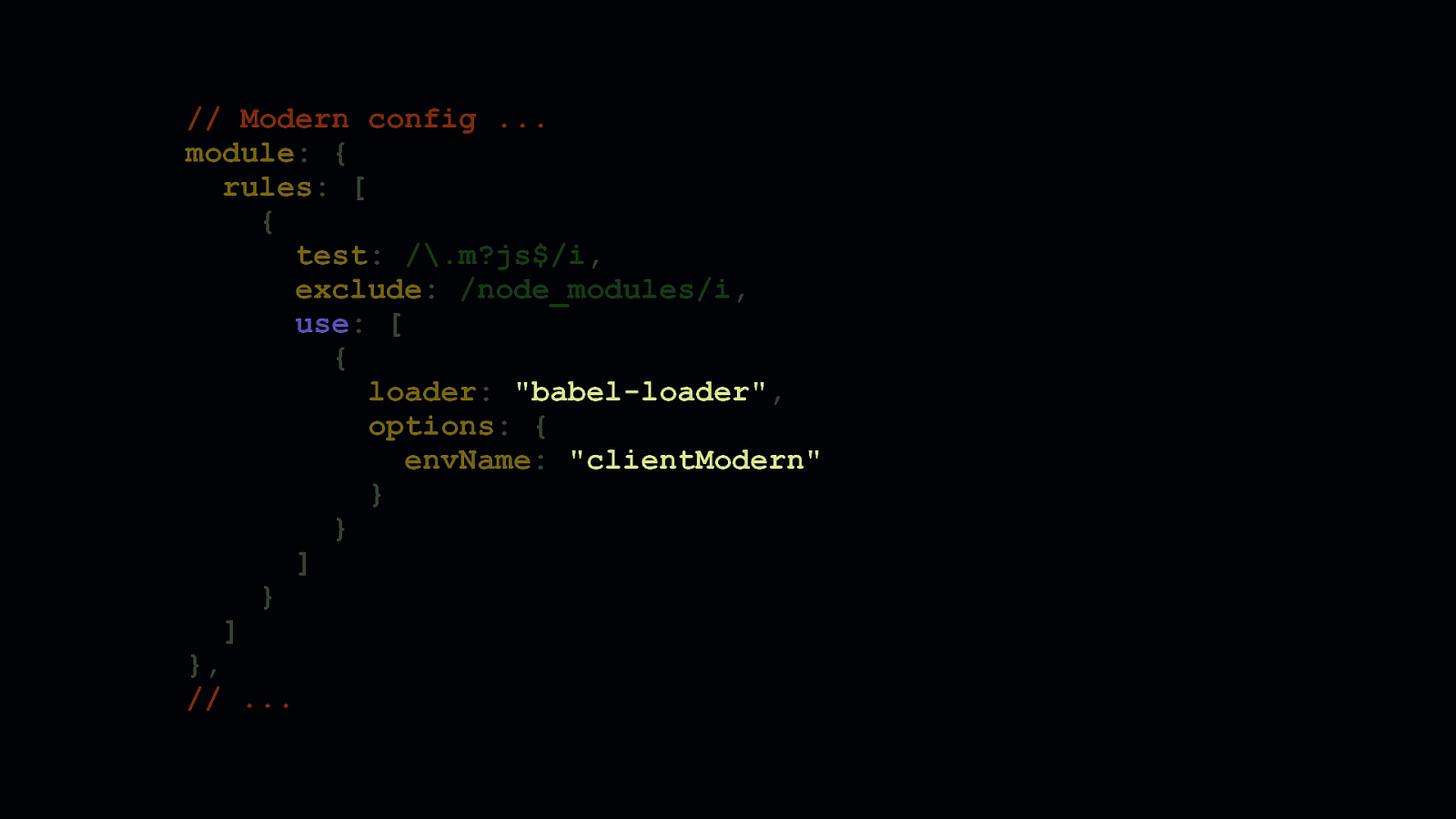
In the modern fork of your webpack config, you can then point to the clientModern Babel config to generate a smaller version of your code for modern browsers.

LEGACY BROWSERS: 68.48 KB - The size difference between legacy and modern bundles depends on the project. Some projects may only see marginal gains to the tune of 5 to 10 percent. Some projects may see much bigger gains, though. This is a webpack bundle analysis of an example app’s legacy bundle. It’s already pretty small at around 68 KB.

MODERN BROWSERS: 26.75 KB -
But with differential serving we can go from small to nano, and deliver this app to modern browsers in just 40% of the size of its legacy counterpart. Even better, when we serve scripts with the type=module attribute, we invoke a stricter and therefore faster parser in Chrome. This means you’re not only shipping less code, but you’re shipping a version of it that will process faster—on Chrome at least.

type=module/nomodule pattern we discussed? It turns out that in IE…
[SHOW IE ICON]…and some versions of Safari… [SHOW SAFARI ICON] - There’s a problem.
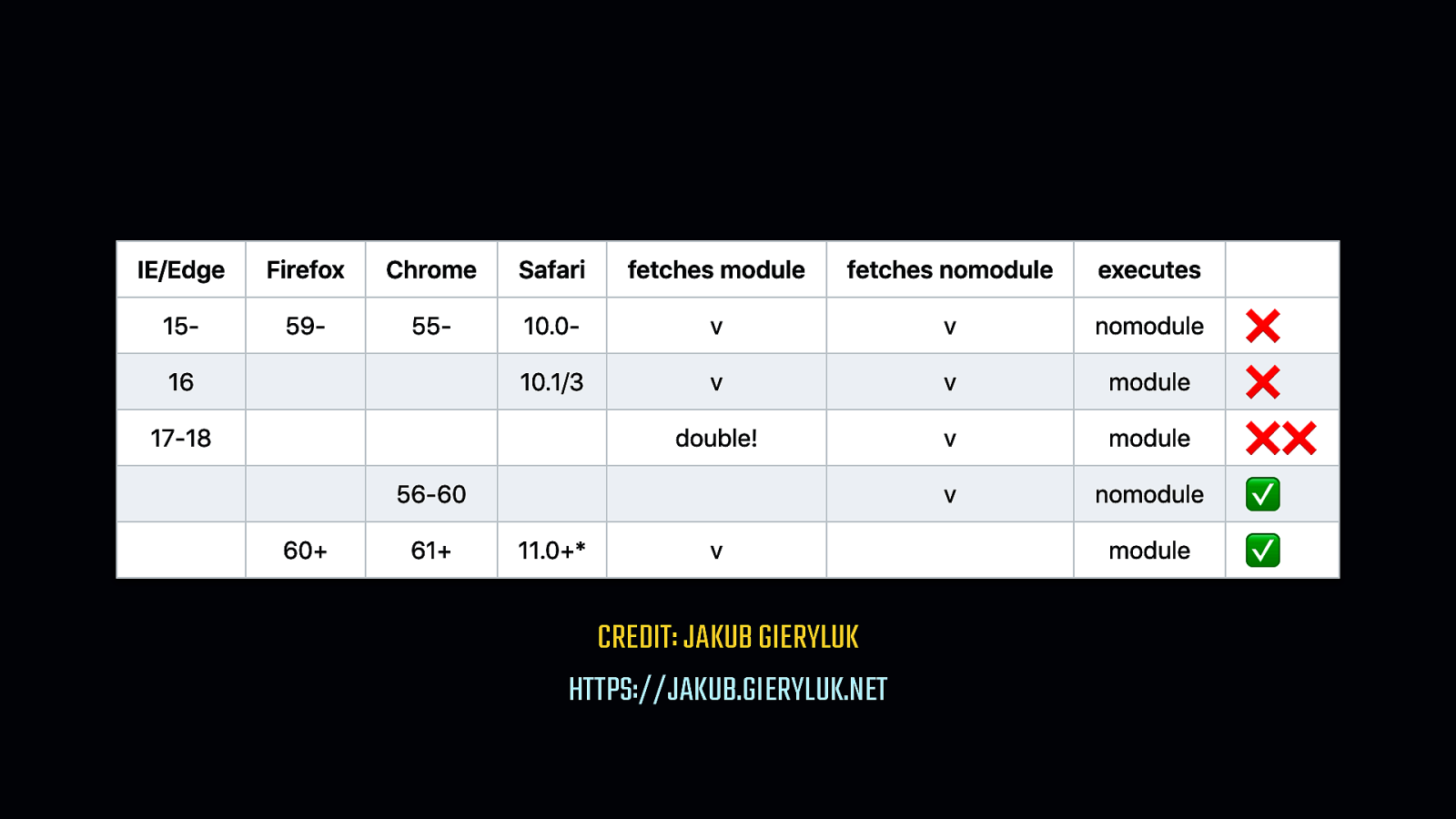
Depending on the browser, both bundles can be downloaded. Worse yet, in select cases, both bundles can also be parsed, compiled, and executed. This is where you have to make a judgement call. Perhaps the majority of your users are likely to be on new, evergreen browsers which don’t suffer this problem. Do you allow those on older browsers to take the hit, knowing the benefit will be still enjoyed by the majority? Or do you solve this problem so scripts are delivered efficiently for everyone? It’s your app. So it’s your call.
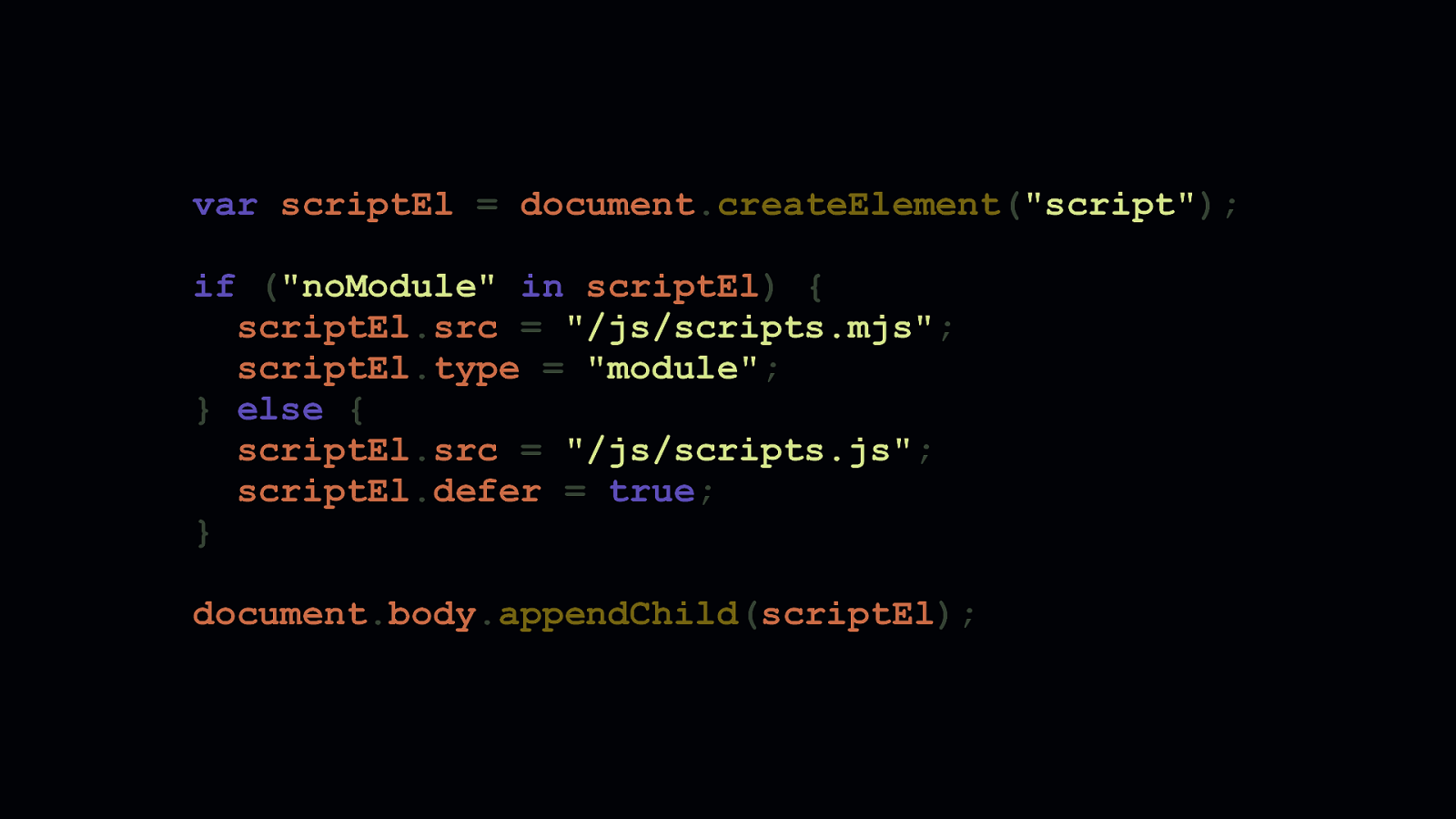
If double downloads are unacceptable to you, there’s another way—though it’s a workaround. In this workaround, you can see we create a <script> element, and infer type=module support by checking to see if the browser supports the nomodule attribute. If it does, we inject a script that points to a modern bundle. If not, we inject a script that points to a legacy bundle. I’ve used this pattern for a recent client of mine, which is a large electronics retailer. It ensures scripts get delivered without double downloads. This is important for them, because their in-store kiosks use IE 11, and will continue to for the foreseeable future. For them, performance is crucial in this setting, so double downloads are unacceptable.

Of course, not all of our JavaScript woes are in our app code. Third party JavaScript is a real problem, and for some, it’s a bigger problem than application code.
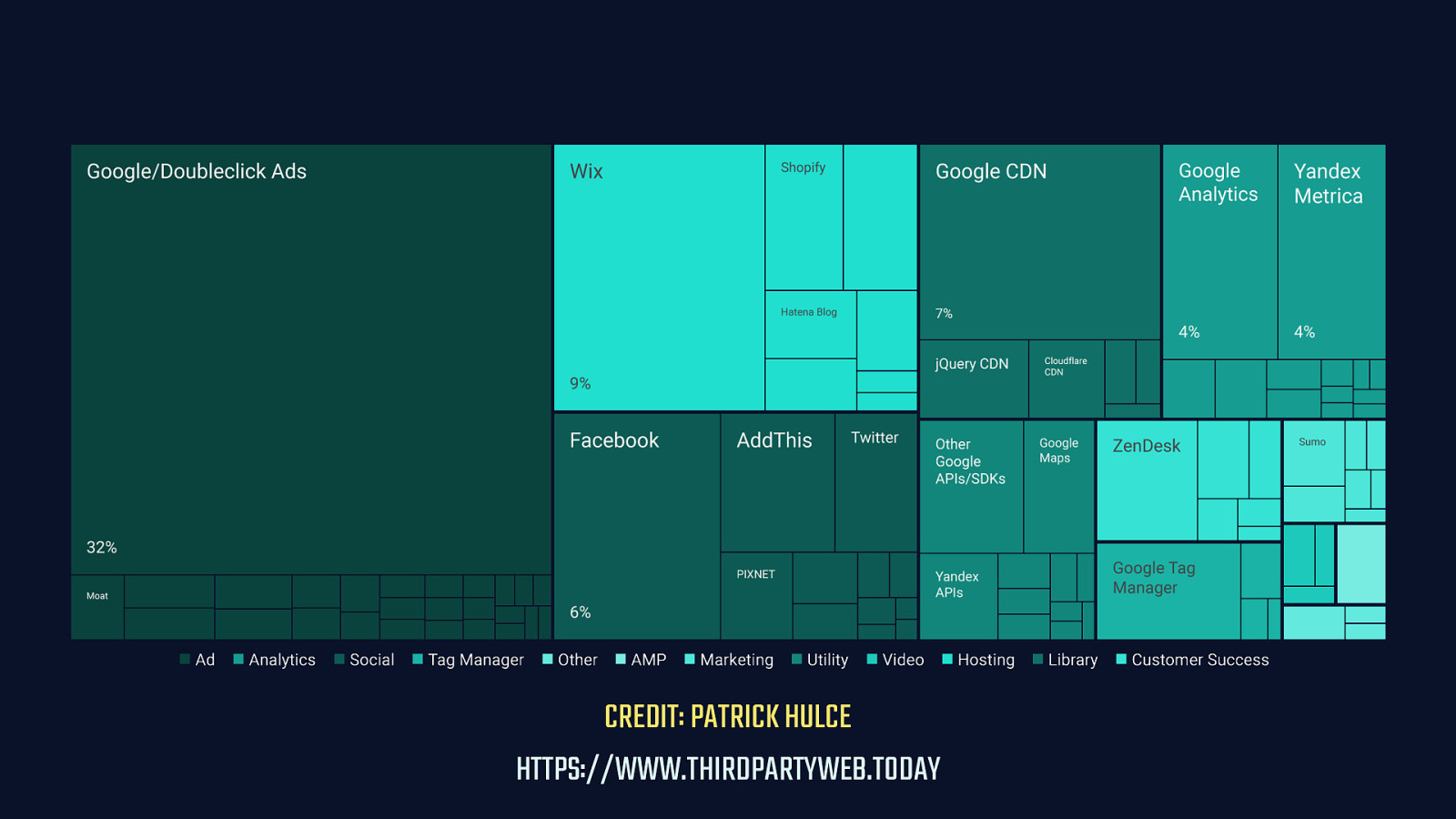
This is a visualization by Patrick Hulce of the performance impact of third party code grouped by organization. The analysis is done on data from the HTTP Archive, which contains data for 4 million sites. The message here is simple: Every third party utility, advertising partner, tag manager, and so on has a performance cost.
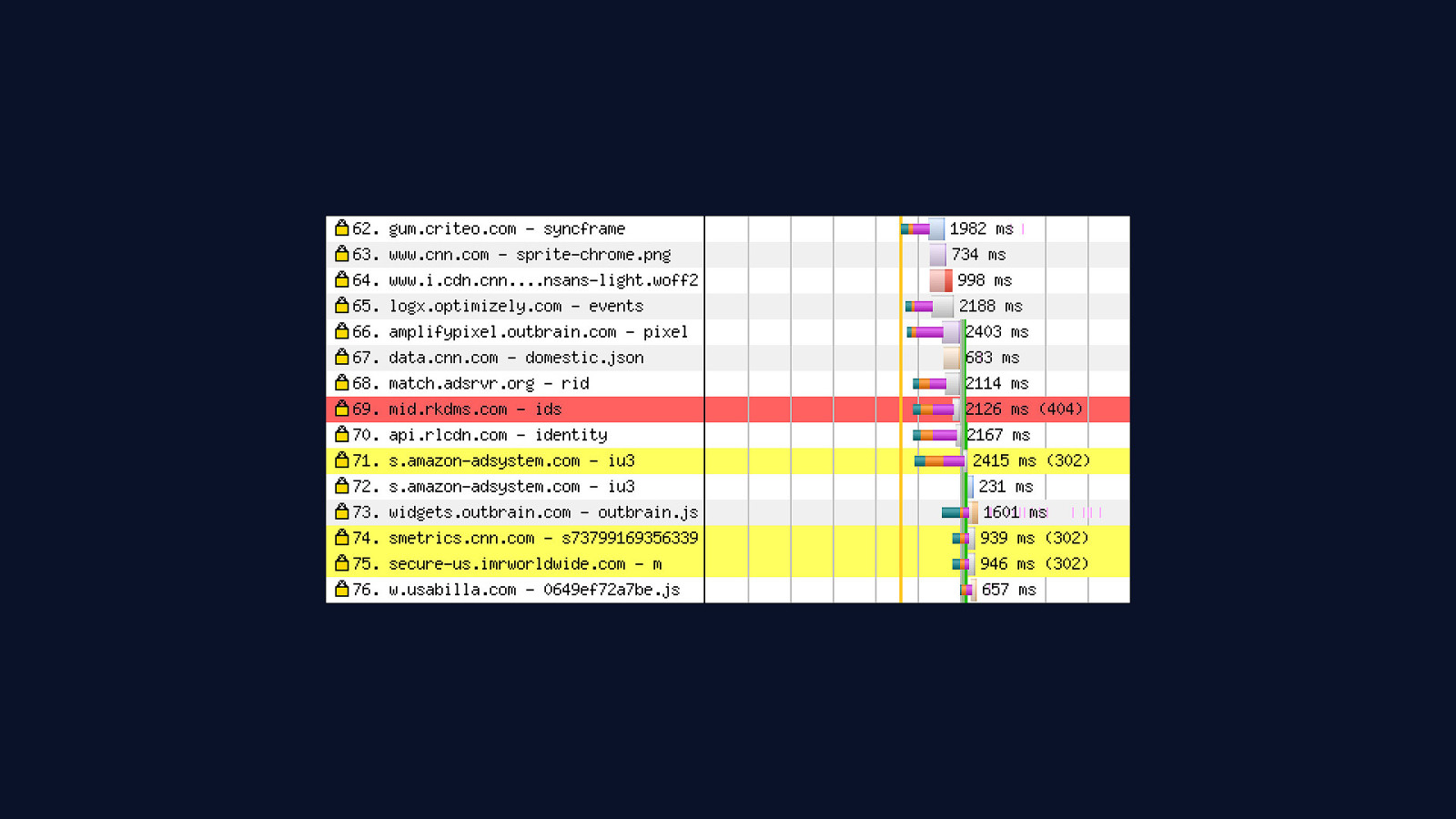
Aside from the overhead third parties add, one of the most damaging things they do to performance is that every unique origin requires a separate connection to be opened to it. This is a three part process: - A DNS lookup must be made to find a third party origin server’s IP. - A connection must then be established to a third party’s server. - And most of the time, we must open a TLS connection to a third party server over HTTPS. This latency can add up to a lot of time people spend waiting for pages to become interactive. The more third parties we add to sites, the more this effect is multiplied.
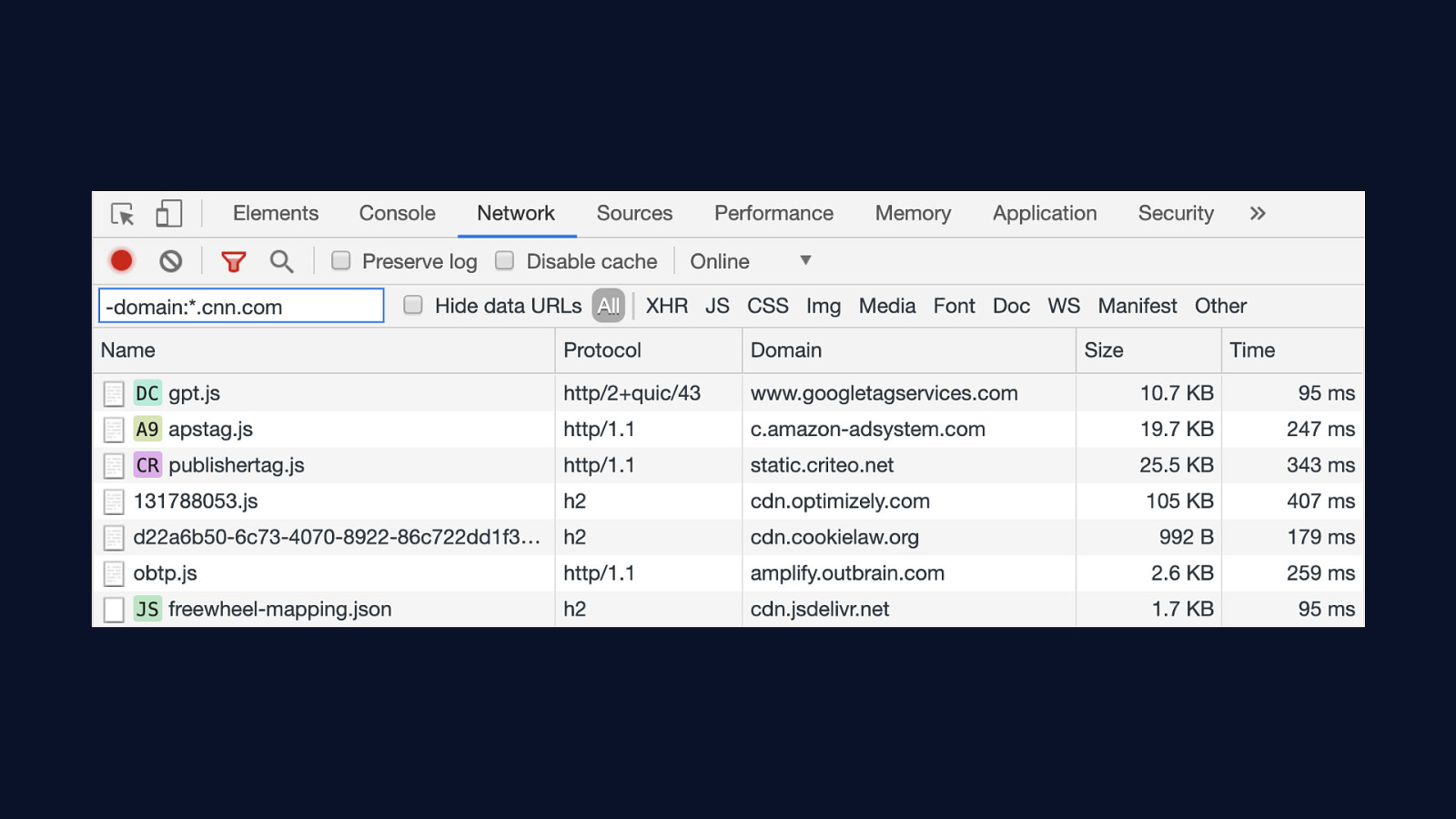
If you want to get a quick idea of how many third party servers are a part of your’s site overall performance picture, you can use this convenient trick. In the network panel of Chrome’s DevTools, you can filter the list by domain. Using CNN’s website as an example, we can filter the list of resources to only third parties by removing all non-cnn.com domains. You can also turn on third party badging in Chrome’s DevTools command palette, which identifies third party resources with a badge to the left of the resource name.

Using Google Fonts as an example, here’s how a single third party can significantly impact performance: - In this WebPageTest timeline, a relatively small site is held up from fully loading and painting text because the browser is forced to wait while fonts are retrieved from Google Fonts. - You’ll notice that DNS, TCP, and TLS time for two domains really holds up the show. - Fonts don’t begin to start downloading until after 4.5 seconds in. - They finish at over 5.5 seconds. For a small site, that’s a long time to be waiting for web fonts, which delays rendering of text by default.

The solution is to self-host. When you self-host third party resources, you eliminate connection latency to other origins by eliminating them entirely. Here, you can see that the only connection we open is to the primary origin—this is a connection we can’t avoid. Our content needs to live somewhere. By cutting Google Fonts out of the picture and self-hosting those resources, we can get fonts downloaded on the client inside of 3.5 seconds. That’s a major improvement.
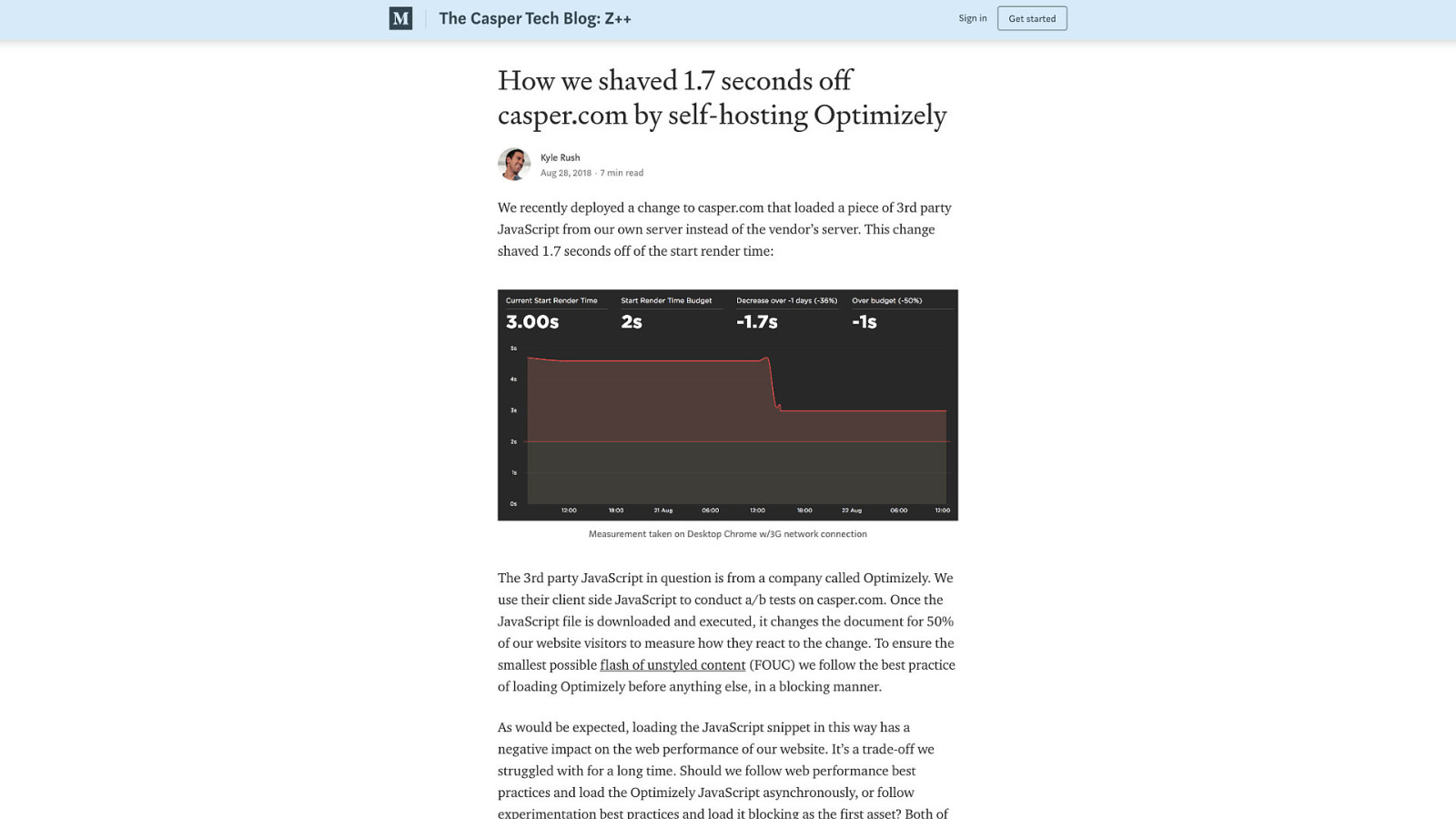
Aside from auditing your third party code and eliminating what you truly don’t need—and you should be doing that anyway—you can extend the idea of self-hosting third party assets to most things. The benefits of doing this are significant, especially where JavaScript is concerned. Optimizely is a popular client-side A/B testing product. My clients use it, and it’s clearly useful to them. The ideal option would be to perform A/B tests on the server and avoid loading large chunks of client-side JavaScript to do this work. But that’s not always possible. In this case study, Casper Mattress was able to reduce start render time by 1.7 seconds by self-hosting Optimizely’s JavaScript. It was an involved process to accomplish this, but the results were worth it. Self host as much third party code as you reasonably can.
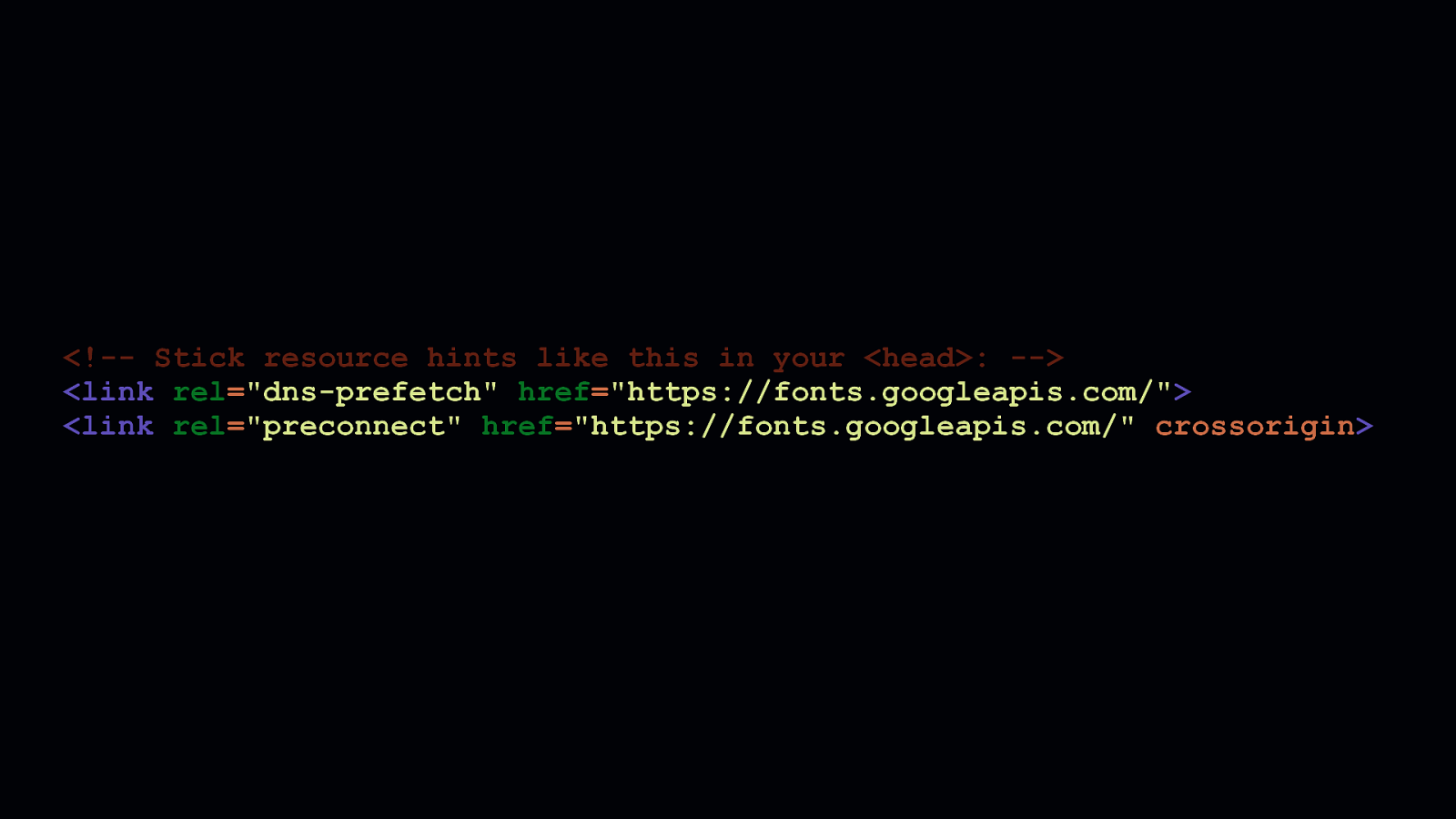
But, that’s not always possible. In such cases, you can use the dns-prefetch and preconnect resource hints to perform DNS lookups or open connections to third party origins as soon as possible. Doing so masks the latency of third party calls to one degree or another. I’ll be direct: this won’t be as beneficial as self-hosting those assets, but it can take some of the sting out of the performance impacts third parties can have on your site.

When we deploy something to the web, we have to be a steward of that thing, and try our level best to make it usable for as many people as possible.

In The United States, many developers live in large cities, which are typically well-served by low latency, high bandwidth broadband and mobile internet connections. But a large portion of the country’s population lives in remote or underserved areas where this isn’t the case. This article by the MIT Technology Review revealed that 58 percent of households in the Cleveland metropolitan area with incomes under $20,000/year had no broadband internet access at all. These are people who often rely on mobile internet connections—often with data caps—to function in an increasingly internet-dependent society.

Even more striking is this passage, in which Pew Research found that fully one third of American adults don’t have an internet connection faster than dial-up in their homes. I doubt this has improved significantly since the article was written. The infrastructure just isn’t there yet to bring these homes into the 21st century.
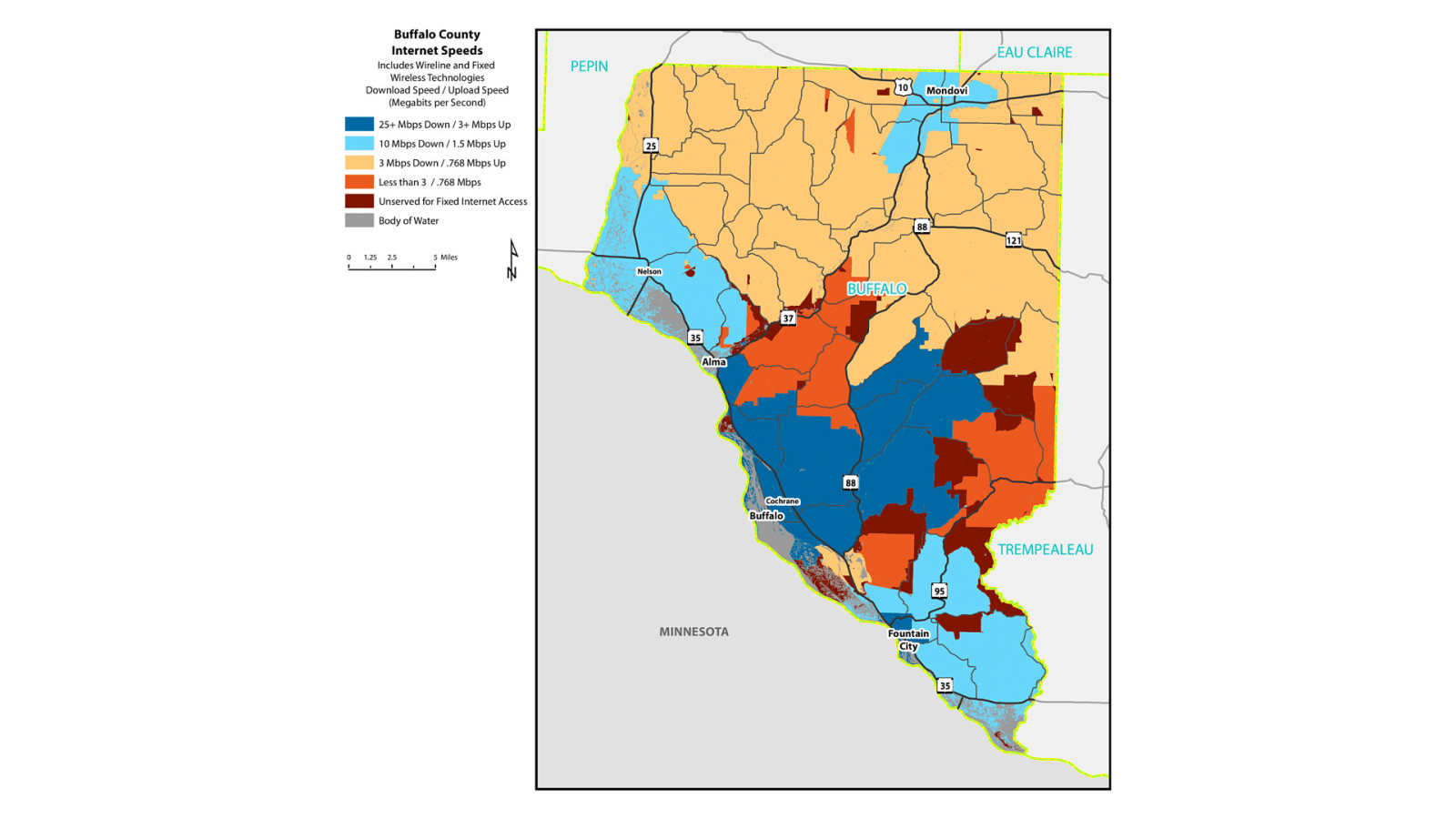
This broadband map of Buffalo County, Wisconsin, the state just east of where I live in Minnesota, is a microcosm of what rural broadband is like in America. If you happen to live near a population center—and have the money—broadband is a choice you have. But once you start getting out in the sticks, broadband starts to look less and less like an option. Until in some places, it’s not an option at all.

The two foundational elements of network performance are latency and bandwidth. If you’re serving a lot of assets on your site, sufficiently high latency or low bandwidth makes your site functionally inaccessible. Thankfully, there’s a technology supported in Chrome and derived browsers called Client Hints.

And ECT.
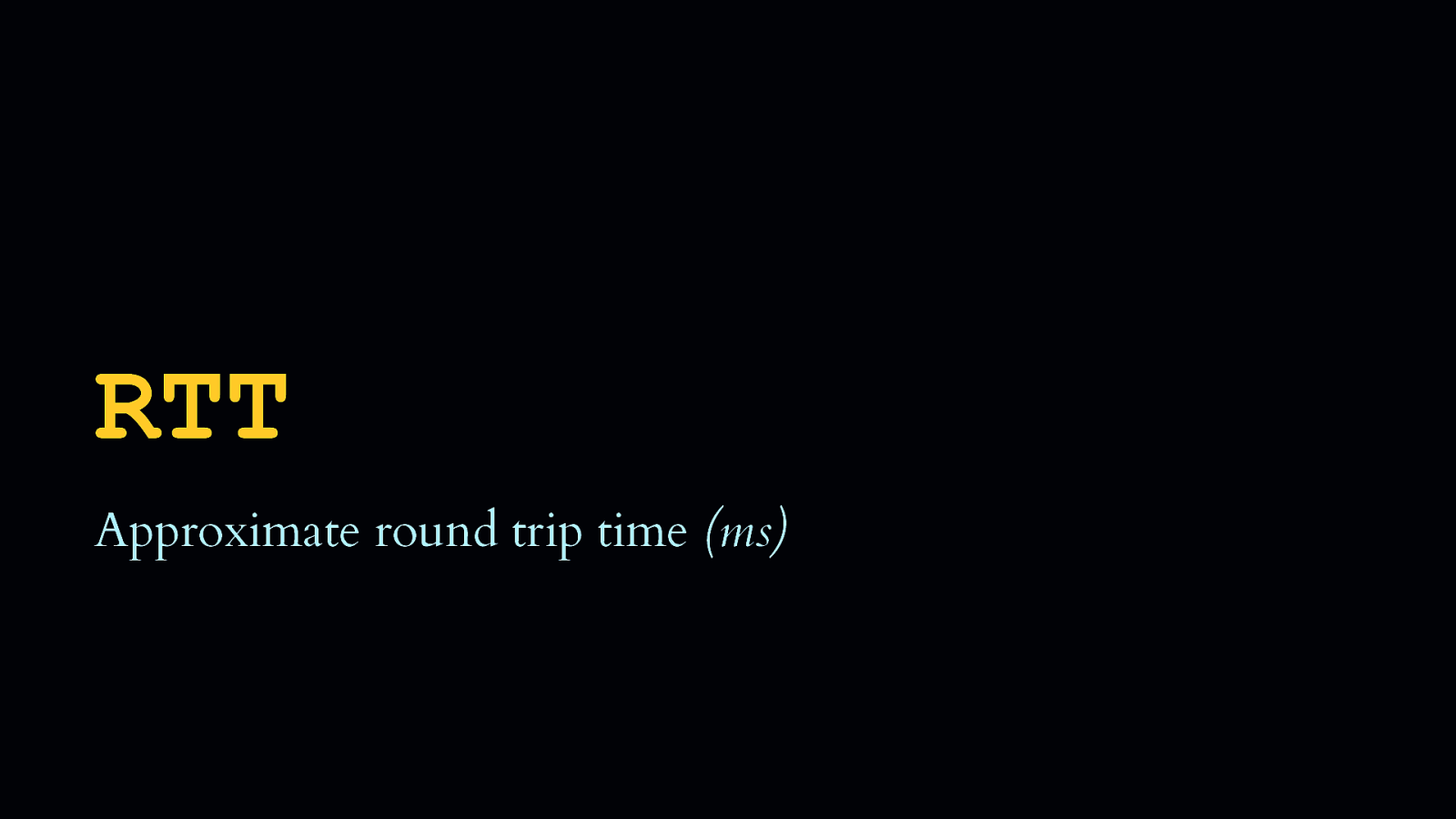
RTT, or Round Trip Time, is the approximate latency a user is experiencing in milliseconds.

Downlink is the approximate downstream bandwidth in kilobits per second.
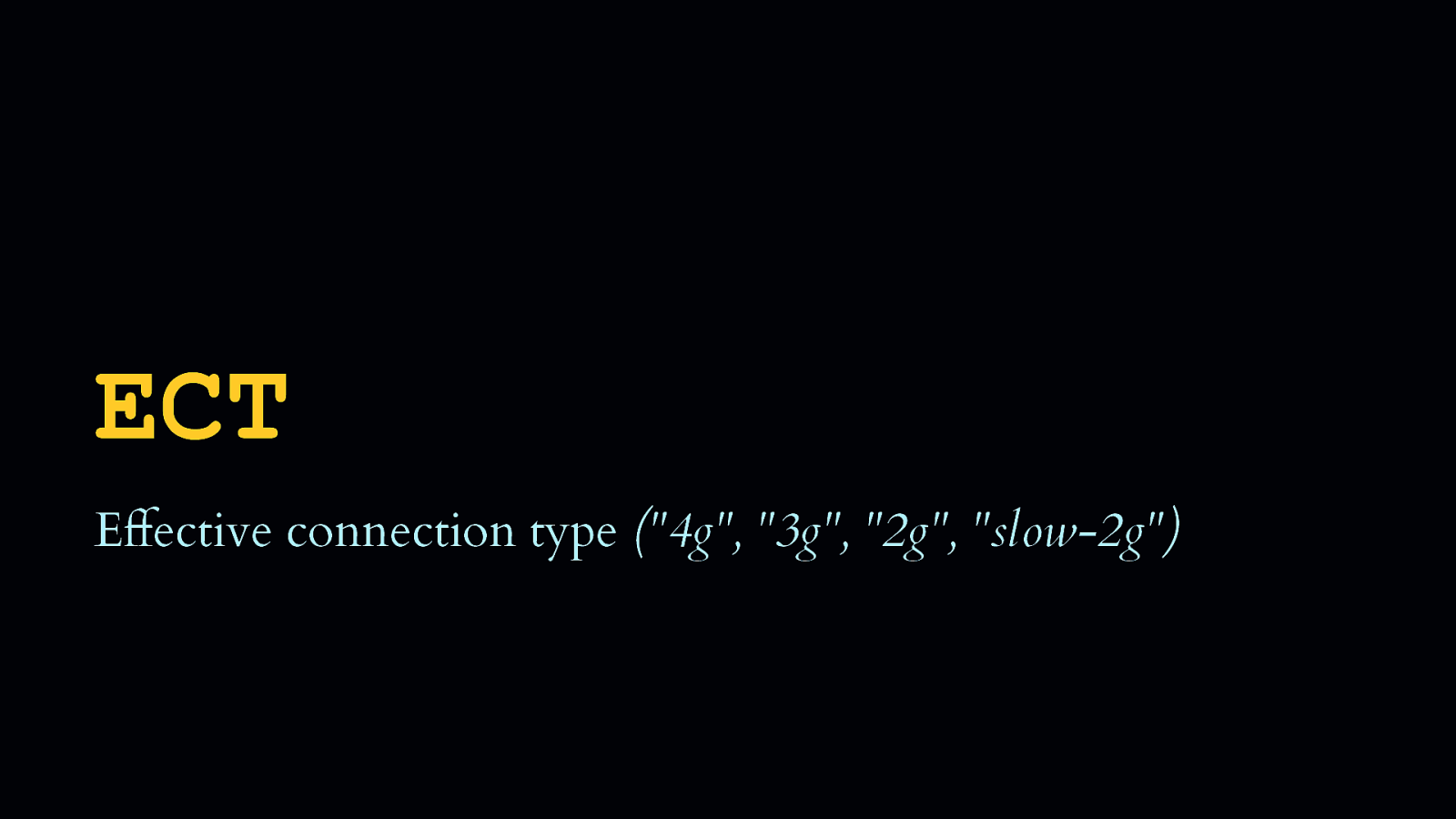
And ECT, or Effective Connection Type, is an enumerated string determined by the browser after it examines the RTT and Downlink. It attempts to categorize the user’s connection based on that information.

Accept-CH HTTP request header.
[SHOW Accept-CH]Accept-CH-Lifetime header.
[SHOW Accept-CH-Lifetime]In the above example, we persist these client hints for a day, but you can supply whatever value is appropriate for your application.

You can access these hints in a server-side language—like PHP as we see here—when they come through as request headers. Here you can see that we initialize a variable with a default effective connection type of ”4g”. We do this in case a browser comes along that doesn’t support client hints, so we assume a default fast connection speed. Then, we check if the ECT hint has been sent as a request header. If it has, we store that header’s value in the ECT variable.
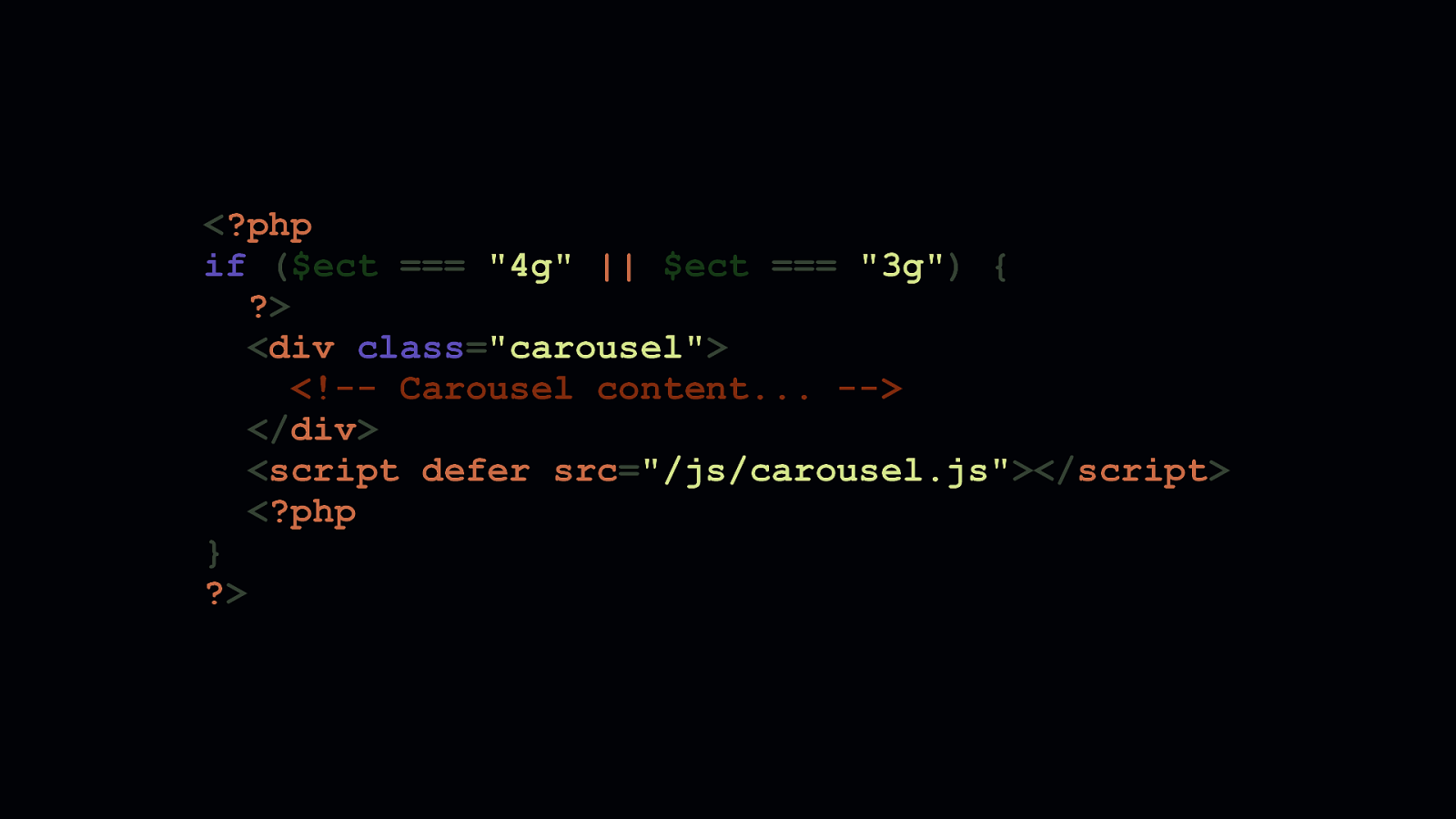
Using this information, we can shape the experiences we create to adapt to the shifting conditions of the network or device accessing them. This is a powerful technology that allows you to create lighter, more focused experiences for the people who need it most. In this example above, we decide that a person will only see a data-intensive carousel if they’re on a fast connection. If a user is on a slow connection, their experience is lightened, and the focus is increased on content that is critical to them.

I like to call this “Adaptive Performance”. I think it’s a fantastic way of compromising between the ideal experience you as a developer worked so hard to build, and an experience that’s more inclusive and accessible to those who maybe otherwise couldn’t access the ideal one you had in mind.

For our trouble, those people will have something they can access quickly, even if bandwidth is lacking and latency is very high.

If you’re interested in learning more about Client Hints, you can see a video on YouTube of a presentation I gave at Full Stack Fest last year that goes in depth on the topic.
Or, if you prefer to read articles, you can check out this guide I wrote for Google that explains Client Hints in similar depth.

Then we need to work backward from there and build something that serves that purpose with precision and care.

Any person in almost any profession loves their tools. They enable us to be craftspeople. Developers are no different. We love the tools that are available to us. We take pride in building great things with them. But unlike, say, the auto mechanic who fixes your car, the tools we choose to do our work have a direct and felt impact by those who use what we make. We don’t always need to burden them with the entire toolchest—or toolshed.

Sometimes it makes more sense to use tools that are smaller and more focused on the actual work. That is to say, your experience as a developer is important, but it is never more important than the user’s experience. If your excitement for a certain set of tools causes you to build things that no longer efficiently serve the purpose you set out to fulfill, it’s time to re-evaluate them.
Thankfully, the ecosystem gives us a lot of options without sacrificing developer experience entirely.
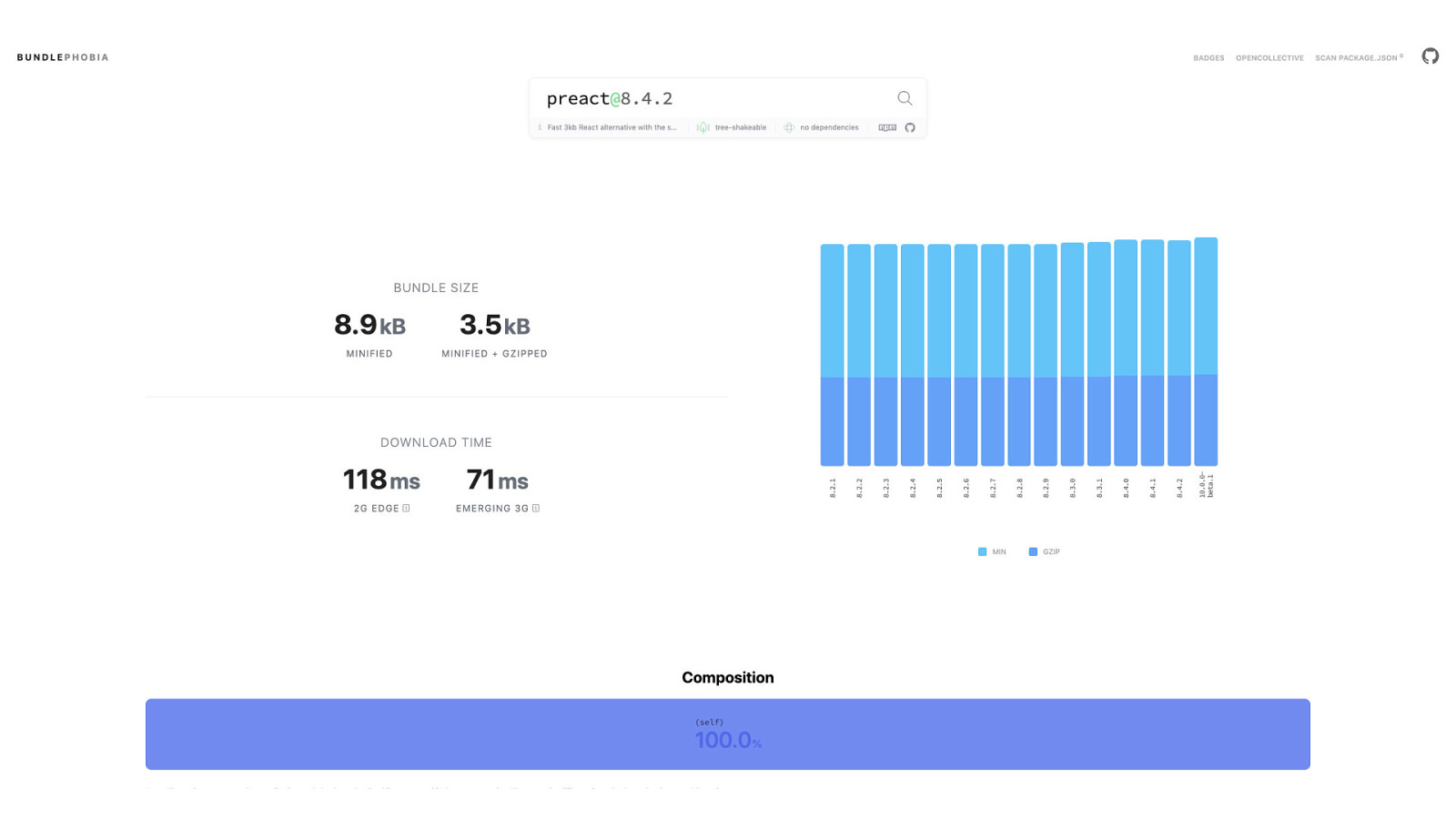
You can always find smaller options that will be felt less by the people who use what you create.
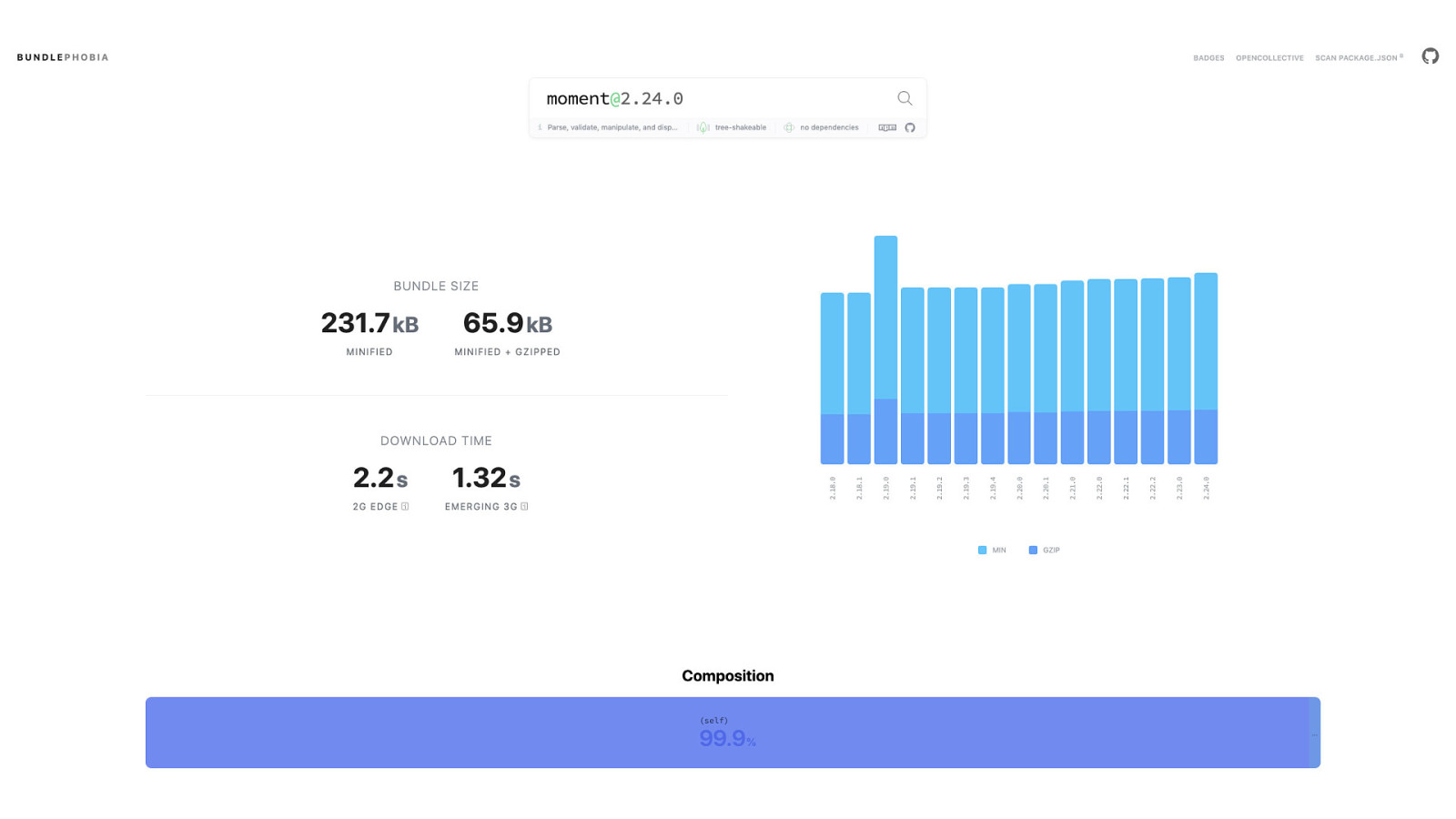
Time and time again, if you look, you can find alternatives to commonly used libraries and frameworks…
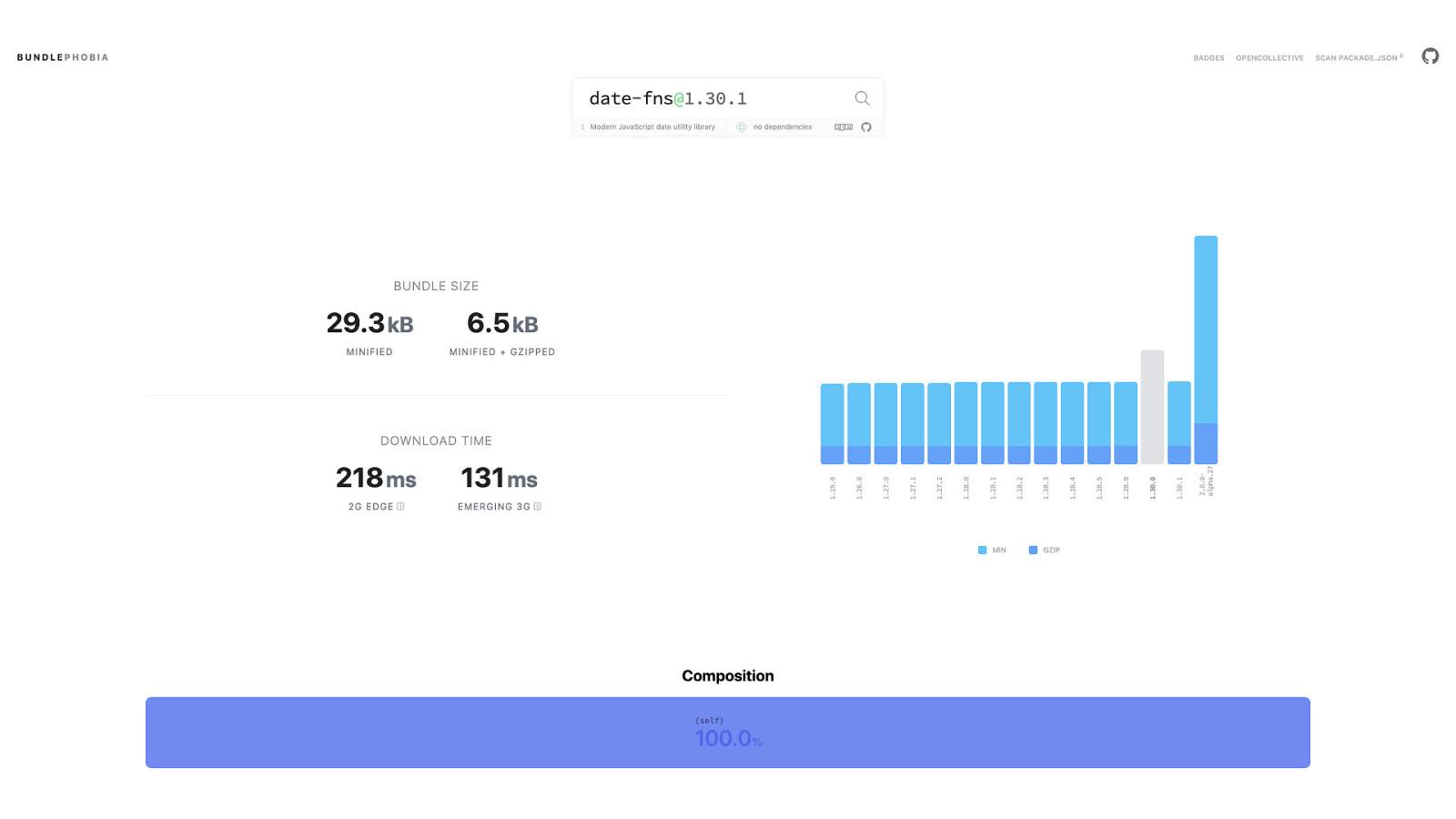
And my hope is that slowly, over time, we can learn to do more with less JavaScript—or even recognize when we don’t need JavaScript—so we can create resilient, fault-tolerant sites that are faster and more accessible for everyone, everywhere.

Thank you.

RESOURCES RESPONSIBLE JAVASCRIPT: PART I alistapart.com/article/responsible-javascript-part-1/ HYBRID LAZY LOADING: A PROGRESSIVE MIGRATION TO NATIVE LAZY LOADING smashingmagazine.com/2019/05/hybrid-lazy-loading-progressive-migration-native BUNDLEPHOBIA bundlephobia.com BABEL 6: LOOSE MODE 2ality.com/2015/12/babel6-loose-mode.html HTTP ARCHIVE httparchive.org THIRD-PARTY WEB thirdpartyweb.today WEBPAGETEST webpagetest.org HOW WE SHAVED 1.7 SECONDS OFF CASPER.COM BY SELF-HOSTING OPTIMIZELY medium.com/caspertechteam/we-shaved-1-7-seconds-off-casper-com-by-self-hosting-optimizely-2704bcbff8ec PAINT THE PICTURE, NOT THE FRAME: HOW BROWSERS PROVIDE EVERYTHING USERS NEED alistapart.com/article/paint-the-picture-not-the-frame THE UNACCEPTABLE PERSISTENCE OF THE DIGITAL DIVIDE technologyreview.com/s/603083/the-unacceptable-persistence-of-the-digital-divide QUICKLINK github.com/GoogleChromeLabs/quicklink TAKE A (CLIENT) HINT! youtube.com/watch?v=md7Ua82fPe4 DNSTRADAMUS github.com/malchata/dnstradamus ADAPTING TO USERS WITH CLIENT HINTS developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/client-hints